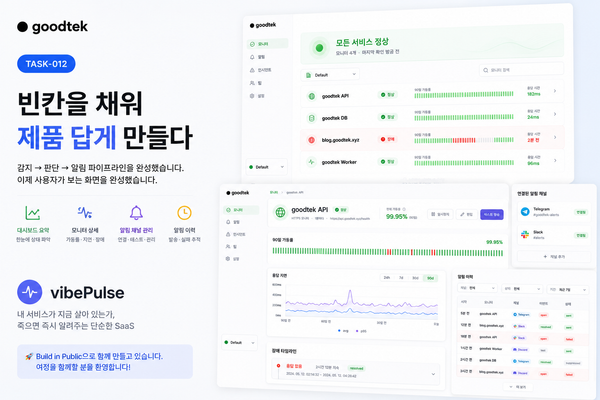
감지 → 판단 → 알림: vibePulse의 심장을 만든 6개의 TASK
goodtek이 만들고 있는 vibePulse는 "내가 만든 웹/API가 지금 살아 있는가"를 확인하고, 죽으면 즉시 알려주는 초간단 생존 확인 SaaS입니다. 이번 글은 그 핵심 파이프라인 — 모니터를 만들고(TASK-006), 주기적으로 찌르고(007), 장애를 판단하고(008), 신호가 끊기면 알아채고(009), 알림을 큐에 태워(010), 슬랙·카카오톡으로 보내기까지(011) — 를 한 호흡에 만든 기록입니다.

goodtek이 만들고 있는 vibePulse는 "내가 만든 웹/API가 지금 살아 있는가"를 확인하고, 죽으면 즉시 알려주는 초간단 생존 확인 SaaS입니다. 이번 글은 그 핵심 파이프라인 — 모니터를 만들고(TASK-006), 주기적으로 찌르고(007), 장애를 판단하고(008), 신호가 끊기면 알아채고(009), 알림을 큐에 태워(010), 슬랙·카카오톡으로 보내기까지(011) — 를 한 호흡에 만든 기록입니다.
며칠을 몰아서 작업했더니, 끝내고 보니 vibePulse가 드디어 "제품"처럼 보이기 시작했습니다. 그 전까지는 로그인하고 모니터 하나 만드는 게 전부였는데, 이제는 진짜로 URL이 죽으면 카톡이 옵니다. 이 글에서는 그 과정에서 내린 결정들과, 몇 번 되돌린 선택들, 그리고 나중에 후회하지 않으려고 일부러 돌아간 길들을 정리합니다.
큰 그림: 우리가 만든 건 결국 한 줄짜리 파이프라인
기능을 6개로 쪼개 놓으니 복잡해 보이지만, 실제로 만든 건 이 한 줄입니다.
[모니터 정의] → [주기적 체크] → [장애 판단] → [알림 발송]
006 007 008/009 010/011조금 더 풀어서 그리면 이렇게 생겼습니다.
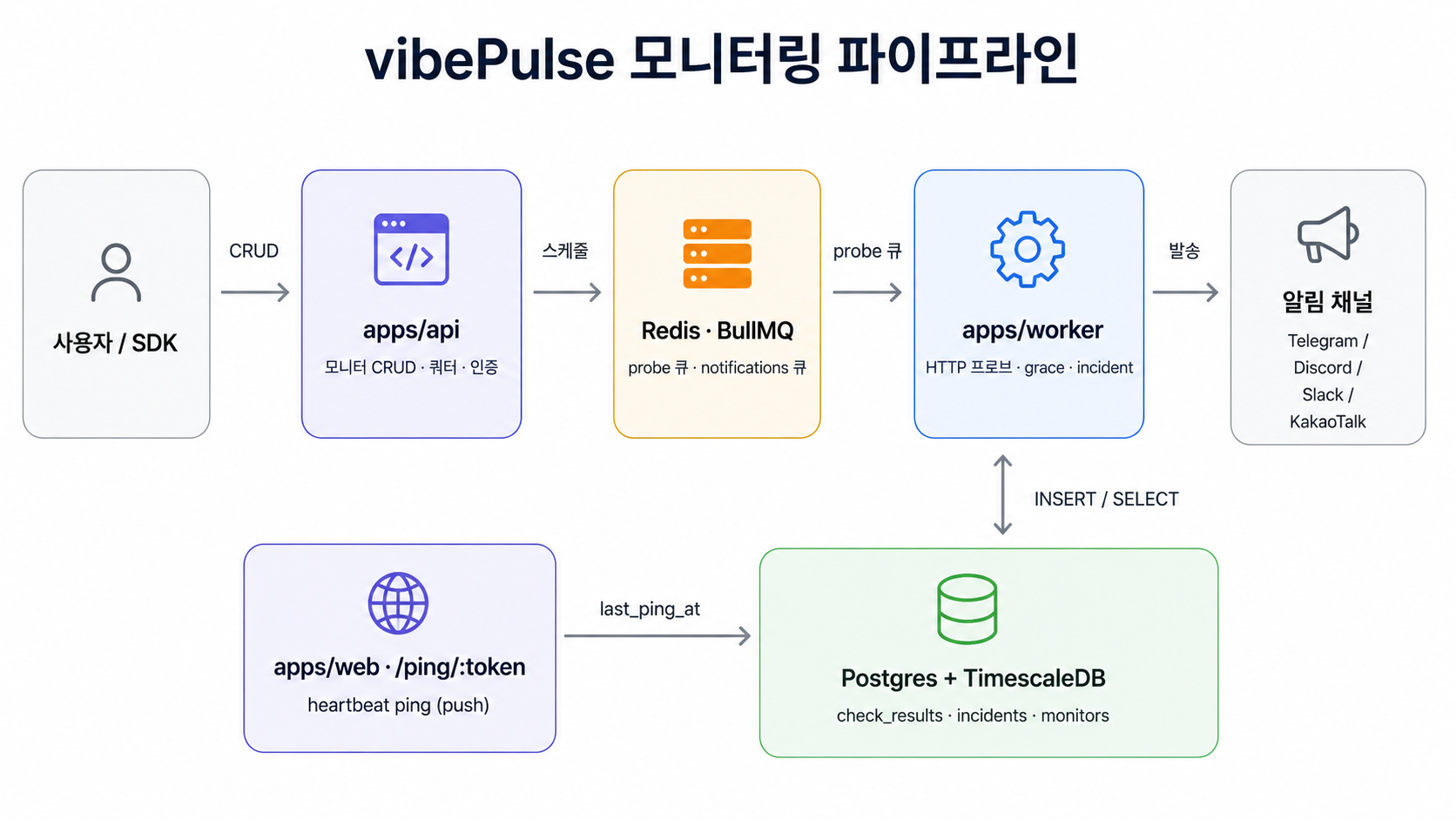
이 그림을 머릿속에 넣고 보면 6개 TASK가 각각 어느 칸을 채웠는지 한눈에 들어옵니다.
TASK-006 — 타입을 두 번 적지 않기로 했다
가장 먼저 한 결정은 "DTO 타입을 프론트·API·SDK에 복붙하지 않는다" 였습니다. 모니터링 제품은 결국 Monitor라는 한 덩어리의 데이터를 프론트도, API도, 나중에 나올 SDK도 똑같이 알아야 합니다. 이걸 각자 정의하기 시작하면 6개월 뒤에 필드 하나 바꿀 때 지옥이 옵니다.
그래서 packages/shared에 zod 스키마를 단일 진실원(single source of truth)으로 박았습니다.
// packages/shared/src/monitor/schemas.ts (발췌)
export const createMonitorBodySchema = z.object({
name: z.string().trim().min(1).max(255),
type: z.enum(['http', 'heartbeat']),
targetUrl: z.string().url().optional(), // http일 때 필수
method: z.enum(['GET', 'HEAD']).default('GET'),
intervalSec: z.number().int(), // 하한은 QuotaService가 검사
timeoutMs: z.number().int().min(1000).max(60000).default(10000),
expectedStatus: z.number().int().min(100).max(599).default(200),
graceSec: z.number().int().min(60).nullable().optional(), // heartbeat 전용
isActive: z.boolean().default(false),
});API 핸들러는 이 스키마로 parse하고, 응답도 같은 스키마로 직렬화합니다. 프론트는 z.infer로 타입을 그냥 가져다 씁니다. 타입을 "공유"하는 게 아니라 계약을 공유하는 거라, 런타임 검증까지 공짜로 따라옵니다.
작지만 중요한 두 가지 결정
1) 남의 리소스는 403이 아니라 404다. 다른 org의 모니터에 접근하면 "권한 없음(403)"이 아니라 "그런 거 없음(404)"을 돌려줍니다. 403은 "여기 뭔가 있긴 한데 넌 못 봐"라는 정보를 흘립니다. 모니터 ID가 UUID라 추측은 어렵지만, 그래도 처음부터 정보 누출 표면을 0으로 두는 게 마음 편합니다.
2) 쿼터는 day-1에 설계하되, 강제는 free 1건만. 결제는 한참 뒤(Phase 3) 일인데도 PLAN_QUOTAS 상수와 QuotaService 훅은 지금 박아뒀습니다. 나중에 결제를 "끼워넣는" 게 아니라, 자리만 비워두는 거죠.
// free 플랜에서 모니터 2개째 생성 시
assertCanCreateMonitor(orgId, body); // → 403 { code: 'quota_exceeded', limit: 1, current: 1 }ping_token은 서버가 crypto.randomBytes로 발급하고 클라이언트 입력은 막았습니다. last_status 같은 상태 캐시 컬럼은 응답에만 노출하고 CRUD로는 못 쓰게 했고요(저건 worker가 쓰는 칸입니다).
검증은 vitest로:
pnpm --filter @vibepulse/shared test
# ✓ 8 tests passed이 "8"이라는 숫자를 기억해두세요. 글 끝에서 다시 만납니다.
TASK-007 — setInterval을 안 쓴 이유
모니터가 생겼으니 이제 주기적으로 찔러야 합니다. 가장 쉬운 길은 API 프로세스 안에서 setInterval 돌리는 겁니다. 그리고 그게 정확히 모니터링 제품이 6개월 뒤 재설계되는 지점입니다.
- API 인스턴스를 2개로 늘리면? 같은 모니터를 2번 찌릅니다.
- 배포로 API가 재시작되면? 그 순간 체크가 멈춥니다.
- 모니터가 1만 개가 되면? API 이벤트 루프가 HTTP 프로브로 막힙니다.
그래서 처음부터 별도 worker + BullMQ(Redis) 큐로 분리했습니다. API는 "스케줄을 등록/해제"만 하는 얇은 프로듀서고, 실제 HTTP 실행은 worker만 합니다.
모니터 생성/수정/삭제 (api)
│ upsertMonitorSchedule / removeMonitorSchedule
▼
probe 큐 (repeatable job, key = "probe:{monitorId}")
│ every: intervalSec * 1000
▼
ProbeWorker (worker) ── executeHttpProbe() ──▶ check_results INSERTrepeatable job의 키를 probe:{monitorId}로 고정한 게 핵심입니다. 모니터 하나당 반복 job은 무조건 1개. interval을 30초→60초로 바꿔도 job이 쌓이지 않고 덮어쓰여집니다.
프로브 판정 로직은 순수 함수로
HTTP 체크 자체는 packages/shared로 빼서 온보딩 화면(생성 직전 미리보기)과 worker가 같은 판정을 쓰게 했습니다.
// packages/shared/src/probe/http-probe.ts (발췌)
const response = await fetch(parsedUrl.toString(), {
method,
redirect: 'follow',
signal: AbortSignal.timeout(request.timeoutMs),
});
const latencyMs = Date.now() - started;
if (response.status === request.expectedStatus) {
return { ok: true, statusCode: response.status, latencyMs };
}
return { ok: false, statusCode: response.status, latencyMs, error: `status_${response.status}` };여기서 한 번 데였습니다: "HTTP 실패 ≠ job 실패"
처음엔 프로브가 실패하면 BullMQ job을 throw 시켰습니다. 그랬더니 대상 서버가 500을 뱉을 때마다 BullMQ가 "어, job 실패네?" 하면서 재시도 + backoff를 걸어버립니다. 우리 입장에선 500은 정상적으로 감지한 비즈니스 결과인데 말이죠.
규칙을 다시 잡았습니다:
상황 | job 결과 | 이유 |
|---|---|---|
대상이 500/타임아웃 | 성공 (ok=false로 기록) | 정상적으로 "장애"를 감지한 것 |
DB 연결 끊김 / 일시 오류 | 실패 → 재시도 | 우리 쪽 인프라 문제만 재시도 |
reconcile: 온보딩이 만든 모니터는 누가 스케줄하나
함정이 하나 더 있었습니다. 온보딩 마법사는 API의 CRUD를 안 거치고 Server Action으로 모니터를 만듭니다(레거시 경로). 그러면 API의 "생성 시 스케줄 등록" 훅이 안 불립니다.
해결책은 worker 기동 시 + 5분마다 도는 reconcile 루프:
// 의사 코드
async reconcileAllActiveHttpMonitors() {
const wanted = await db.find({ type: 'http', isActive: true });
const existing = await queue.getRepeatableJobs();
// wanted엔 있는데 없으면 upsert, existing엔 있는데 DB에 없으면 remove
}이렇게 하면 "어떤 경로로 만들어졌든 활성 HTTP 모니터는 결국 스케줄된다"가 보장됩니다. API 훅은 즉시성(빠른 반영), reconcile은 정합성(드리프트 복구) — 두 개를 같이 두는 게 분산 스케줄링에서 마음이 편합니다.
pnpm --filter @vibepulse/shared test # ✓ 15 passed (http-probe + schedule client)
pnpm build # db, sdk, shared, api, worker, web 전부 OKTASK-008 — "장애"를 판단하는 일은 생각보다 미묘하다
체크 결과는 쌓이는데, 그 자체로는 알림을 보낼 수 없습니다. 한 번 500 떴다고 "장애!"라고 카톡을 쏘면 그건 알림이 아니라 스팸입니다. 그래서 incident(장애) 라이프사이클이 필요합니다: open → (acknowledged) → resolved.
판단 규칙을 코드 곳곳에 흩뿌리지 않고, 순수 함수 하나로 모았습니다. 이게 이번 6개 TASK 중에서 제일 마음에 드는 코드입니다.
// packages/shared/src/incident/incident-transition.ts
export function evaluateIncidentTransition(input: {
consecutiveFails: number;
probeOk: boolean;
hasActiveIncident: boolean;
}): 'none' | 'open' | 'resolve' {
if (input.probeOk && input.hasActiveIncident) {
return 'resolve';
}
if (
!input.probeOk &&
input.consecutiveFails >= INCIDENT_FAILURE_THRESHOLD && // = 3
!input.hasActiveIncident
) {
return 'open';
}
return 'none';
}DB도, Redis도, 시간도 안 들어갑니다. 입력 3개 → 출력 1개. 그래서 테스트가 공짜입니다. "2번 실패까지는 none, 3번째에 open, 4·5번째도 none(중복 open 금지), 성공 1번에 resolve" — 이걸 다 단위 테스트로 박아도 mock이 필요 없습니다.
N=3, 그리고 "동시에 active incident는 최대 1건"
연속 실패 임계값은 INCIDENT_FAILURE_THRESHOLD = 3으로 고정했습니다. 그리고 같은 모니터에 active incident가 2건 생기는 걸 막으려고 서비스 가드 + DB partial unique index를 둘 다 걸었습니다. 애플리케이션 레벨 가드는 멱등성을 위해, DB 인덱스는 경합(race) 최후의 방어선으로요.
CREATE UNIQUE INDEX uq_incidents_monitor_active
ON incidents (monitor_id)
WHERE status IN ('open', 'acknowledged');TASK-007에서 한 실수를 여기서 고쳤다
빌드인 퍼블릭이니 솔직하게. TASK-007에서는 "첫 실패에 바로 last_status = down"으로 적었습니다. 그런데 그러면 일시적인 단발 500에도 대시보드가 빨개집니다. TASK-008에서 규칙을 바로잡았습니다:
// 3회 미만 실패 → operational 유지 (단발 실패는 consecutiveFails로만 표시)
// incident open → down, resolve → operational
export function resolveMonitorLastStatus({ probeOk, hasActiveIncident, transition }) {
if (probeOk) return 'operational';
if (transition === 'open' || hasActiveIncident) return 'down';
return 'operational';
}가동률은 절대 원본을 풀스캔하지 않는다
check_results는 TimescaleDB hypertable이라 며칠만 지나도 수백만 행이 됩니다. "지난 7일 가동률"을 계산하려고 이걸 풀스캔하면 그날로 망합니다. 그래서 continuous aggregate 롤업(check_results_1m / _1h / _1d)에서만 읽습니다.
-- 7일 = _1h 롤업에서
SELECT
SUM(ok_count)::float / NULLIF(SUM(total), 0) AS uptime_ratio,
AVG(avg_latency) AS avg_latency_ms
FROM check_results_1h
WHERE monitor_id = $1 AND bucket >= now() - interval '7 days';기간별로 어떤 롤업을 쓸지도 미리 정해뒀습니다:
기간 | 사용 롤업 |
|---|---|
24h |
|
7d / 30d |
|
90d |
|
pnpm --filter @vibepulse/shared test # ✓ 24 passed (incident transition 9건 포함)
pnpm --filter @vibepulse/api test # ✓ 22 passed (incidents + uptime)TASK-009 — 죽었는데 아무도 안 찌르는 경우 (dead man's switch)
지금까지는 우리가 밖에서 URL을 찌르는 pull 방식이었습니다. 그런데 cron job, 배치, 백그라운드 워커처럼 밖에서 찌를 URL이 없는 것들은요? 이건 거꾸로 해야 합니다. "걔가 우리한테 주기적으로 신호를 보내고, 신호가 끊기면 죽은 걸로 판단" — 이게 heartbeat, 일명 dead man's switch입니다.
정상: ping ping ping ping ping ... → operational
│
장애: ping ping ping ✗ (interval + grace 초과) → incident openoverdue 판정 공식은 한 줄입니다:
// now > last_ping_at + interval_sec + grace_sec → overdue
const deadlineMs = lastPingAt.getTime() + (intervalSec + graceSec) * 1000;
return now.getTime() > deadlineMs;grace_sec을 따로 둔 이유는, cron이 1분 주기여도 네트워크 지연이나 약간의 흔들림은 봐줘야 하기 때문입니다. "1분마다 + 2분 봐주기" 같은 식이죠.
첫 ping을 기다릴 때 / paused일 때
엣지 케이스가 알림 품질을 좌우합니다.
- 아직 한 번도 ping이 안 왔으면(
last_ping_at IS NULL) → incident 안 만듭니다. "설치 직후 첫 ping 대기" 상태지 장애가 아니니까요. - 모니터가 paused면 → ping은 받아주되(=
last_ping_at은 갱신) grace 평가는 스킵.
고빈도 ping을 다 저장하면 안 된다 (다운샘플)
heartbeat는 초 단위로 올 수도 있습니다. 이걸 다 check_results에 INSERT하면 시계열이 폭발합니다. 그래서 분당 최대 1행으로 다운샘플:
// packages/shared/src/heartbeat/downsample.ts
export function shouldInsertCheckResult({ lastCheckResultTs, now }) {
if (!lastCheckResultTs) return true;
return minuteBucket(lastCheckResultTs).getTime() !== minuteBucket(now).getTime();
}같은 분 안에 10번 ping이 와도 last_ping_at만 갱신하고 행은 1개만 남깁니다.
ping은 왜 API가 아니라 web으로 받았나
이게 좀 고민한 결정입니다. ping URL(/ping/:token)을 받는 곳을 apps/api로 둘까 apps/web으로 둘까. 결론은 web의 locale-free 라우트 핸들러(app/ping/[token]/route.ts)였습니다.
이유:
- ping URL은 인증 불필요한 공개 URL이고, locale 프리픽스가 붙으면 안 됩니다(
/ko/ping/...같은 게 발급되면 끔찍하죠). web의app/[locale]/바깥에 두면 URL이 영구·고정됩니다. - web이 api를 HTTP로 다시 호출하게 만들면 지연 + 순환 의존이 생깁니다. 그래서 ingest 코어 로직을
packages/db로 빼서 web이 직접pg로 처리하게 했습니다.
인증이 필요한 POST /v1/heartbeat(프로젝트 API 키 검증) 경로는 따로 api에 두고, 둘 다 같은 ingest 코어를 부릅니다. open/resolve도 TASK-008의 IncidentService를 그대로 재사용했고요. 새 incident 서비스를 또 만들지 않은 게 핵심입니다.
curl -fsS -m 10 --retry 3 "$HB_BASE_URL/ping/<token>" # 온보딩에 그대로 노출되는 예시
pnpm --filter @vibepulse/shared test # ✓ 36 passedTASK-010 — 알림은 절대 트랜잭션 안에서 보내지 않는다
이제 진짜 알림입니다. 여기서 제일 중요한 규칙 하나:
DB 트랜잭션 안에서 외부 HTTP(텔레그램/디스코드)를 호출하지 마라.
incident를 INSERT하는 트랜잭션 안에서 텔레그램 API를 부르면, 텔레그램이 느려질 때 DB 트랜잭션이 같이 길어지고, 텔레그램이 죽으면 incident 기록 자체가 롤백됩니다. "알림 실패가 장애 판단을 망가뜨리는" 최악의 결합이죠.
그래서 구조를 이렇게 잡았습니다:
[probe/heartbeat 트랜잭션]
incident INSERT/UPDATE ──commit──┐
▼ (커밋 이후에만)
NotificationProducer.enqueueForIncident()
│ 채널당 1 job
▼
notifications 큐 (BullMQ)
▼
NotificationWorker (consumer)
├─ idempotency 체크 (Redis SET NX)
├─ registry → Telegram / Discord adapter
└─ notification_log INSERT (sent/failed/suppressed)incident 행은 이미 커밋됐으니, 알림 enqueue가 실패해도 그건 그냥 에러 로그 한 줄이지 상태가 깨지진 않습니다.
채널 추상화: 슬랙을 하드코딩하지 않기
알림을 코드에 if (slack) {...}로 박으면 채널 하나 추가할 때마다 코어를 건드려야 합니다. 그래서 NotificationChannelSender 인터페이스 + registry 패턴으로:
interface NotificationChannelSender {
readonly type: string; // 'telegram' | 'discord' | ...
send(ctx): Promise<void>;
}
// registry가 channel.type으로 adapter를 골라줍니다.TASK-010에서는 Telegram + Discord만 구현했습니다. adapter는 fetch + 8초 타임아웃이 전부고, config가 누락되면 조용히 성공하지 말고 명시적으로 throw 하도록 했습니다. "보낸 줄 알았는데 안 갔다"가 모니터링 제품에서 제일 무섭거든요.
멱등성: 같은 장애로 카톡 2번 안 오게
worker는 재시도가 있고, 분산 환경에선 같은 job이 두 번 돌 수도 있습니다. 그래서 발송 직전에 Redis로 멱등성 키를 잠급니다.
키: notify:{incidentId}:{channelId}:{event}
SET NX + TTL 7일
→ 이미 있으면 발송 스킵 + notification_log.status = 'suppressed'발송 결과는 셋 중 하나로 남깁니다: sent / failed / suppressed. 운영할 때 이 세 단어만 grep하면 무슨 일이 있었는지 다 보입니다.
pnpm --filter @vibepulse/shared test # ✓ 46 passed (notification 10건 포함)
pnpm --filter @vibepulse/worker test # ✓ Telegram/Discord adapter greenTASK-011 — 슬랙, 카카오톡, 그리고 중복 제거
추상화를 잘 짜두면 채널 추가는 거의 즐거운 일이 됩니다. TASK-011에서 Slack과 KakaoTalk을 붙였는데, producer/consumer/큐/멱등성은 손도 안 댔습니다. registry에 adapter 2개 등록한 게 거의 전부였어요. 이게 TASK-010에서 추상화에 시간을 쓴 보상입니다.
- Slack: Incoming Webhook. Discord와 사실상 같은 패턴(
{ webhookUrl }에 POST). 가장 빨리 붙습니다. - KakaoTalk: "나에게 보내기"(
memo/default/send) API + 사용자 OAuth 토큰. 비즈니스 채널·알림톡 심사는 한참 뒤(TASK-020)로 미루고, 일단 "내 카톡으로 장애 알림 받기"를 먼저.
카카오 OAuth는 로그인 세션과 분리된 알림 전용 콜백 경로로 처리했습니다. 로그인용 카카오 연동과 알림 발송용 토큰은 다른 scope(talk_message)가 필요하고, 섞으면 둘 다 꼬입니다.
채널 CRUD API + 모니터 ↔ 채널 연결
이번에 채널을 관리하는 API도 추가했습니다. 채널 생성/수정/삭제, 모니터에 채널 연결(M:N, PUT으로 전체 교체), 그리고 테스트 발송까지.
POST /v1/projects/:projectId/notification-channels # 채널 생성
PUT /v1/monitors/:monitorId/notification-channels # { channelIds } 전체 교체
POST /v1/notification-channels/:channelId/test # 테스트 발송테스트 발송은 incident 경로를 그대로 재사용하되 event = 'test'로 분기합니다. 새 코드를 거의 안 짜고 기존 파이프라인에 태운 거죠.
dedupe: 같은 webhook 두 번 등록해도 한 번만
여기서 재밌는 디테일. 사용자가 "모니터링 채널"과 "에러 채널"이라는 이름으로 같은 Slack webhook을 두 번 등록할 수 있습니다. 그러면 장애 때 슬랙 알림이 2번 옵니다. 이걸 막으려고 목적지(destination) 기준 dedupe 순수 함수를 둡니다.
// packages/shared/src/notification/dedupe.ts (발췌)
if (channel.type === 'discord' || channel.type === 'slack') {
return `${channel.type}:${normalizeWebhookUrl(webhookUrl)}`; // URL 정규화 후 비교
}
if (channel.type === 'telegram') {
return `telegram:${botToken}:${chatId}`;
}
if (channel.type === 'kakaotalk') {
return kakaoUserId ? `kakaotalk:user:${kakaoUserId}` : `kakaotalk:token:${accessToken.slice(0,16)}`;
}규칙은 이렇게 정리됩니다:
케이스 | 결과 |
|---|---|
같은 Slack webhook 2개 채널 | dedupe → 1 job |
같은 type, 다른 목적지 (텔레그램 봇 2개) | 2 job (둘 다 보냄) |
즉 "같은 곳으로 두 번"은 막되, "다른 곳으로 두 번"은 존중합니다.
토큰은 절대 그대로 안 돌려준다
채널 config에는 봇 토큰, webhook URL, 카카오 액세스 토큰이 들어갑니다. API 응답과 로그에서는 전부 마스킹(뒤 4자리만 노출)했습니다. v1에선 DB 레벨 암호화까지는 안 했지만(후속 과제), 적어도 응답으로 평문 토큰이 새는 일은 없습니다.
pnpm --filter @vibepulse/shared test # ✓ 58 passed (notification 22건)
pnpm --filter @vibepulse/worker test # ✓ 9 passed (Slack/Kakao 포함)
pnpm --filter @vibepulse/api test # ✓ 27 passed (kakao-oauth 포함)숫자로 보는 6개의 TASK
빌드인 퍼블릭의 작은 즐거움 하나는 테스트 개수가 쌓이는 걸 보는 겁니다. packages/shared(우리 도메인 로직의 심장)의 통과 테스트 수만 따라가 봤습니다.
TASK-006 ████████ 8
TASK-007 ███████████████ 15
TASK-008 ████████████████████████ 24
TASK-009 ████████████████████████████████████ 36
TASK-010 ██████████████████████████████████████████ 46
TASK-011 ██████████████████████████████████████████████████████ 58
└───────────────── shared 패키지 누적 통과 테스트 ─────────────────┘도메인 판단 로직(프로브 판정, incident 전이, grace 공식, dedupe, 템플릿)을 전부 순수 함수 + 단위 테스트로 짠 덕분에, 인프라(DB/Redis) 없이도 핵심 규칙이 다 검증됩니다. 6개 TASK 내내 pnpm lint와 pnpm build는 매번 green이었고, 빌드는 항상 db / sdk / shared / api / worker / web 6개 패키지를 통과시켰습니다.
각 TASK가 어느 칸을 채웠는지 한 장으로:
TASK | 한 줄 요약 | 핵심 결정 |
|---|---|---|
006 | 모니터 CRUD + 공유 계약 | zod 단일 진실원, 404 스코프, 쿼터 day-1 |
007 | 스케줄러 + HTTP 프로브 worker | 큐 분리, repeat key 1개, reconcile 루프 |
008 | incident 라이프사이클 + 가동률 | 순수 함수 전이, N=3, 롤업만 조회 |
009 | heartbeat + dead man's switch | grace 공식, 분당 1행, ping은 web에서 |
010 | 알림 추상화 + notifications 큐 | post-commit enqueue, 멱등성, Telegram/Discord |
011 | Slack/KakaoTalk + 채널 API | adapter만 추가, destination dedupe, 토큰 마스킹 |
정리하며: 다시 해도 똑같이 할 것들
며칠을 압축해서 달렸지만, 빨리 가려고 미래를 저당잡히진 않으려 했습니다. 돌아봤을 때 "이건 처음부터 이렇게 하길 잘했다" 싶은 것들:
- 계약을 공유하지, 타입을 복붙하지 않는다.
packages/shared의 zod 스키마 하나로 검증·타입·문서가 다 따라옵니다. - 체크 실행은 무조건 큐 + 별도 worker.
setInterval은 데모까진 되지만 제품은 못 됩니다. - 도메인 판단은 순수 함수로. incident 전이, grace, dedupe를 함수로 빼니 테스트가 공짜고 버그가 안 숨습니다.
- 트랜잭션 안에서 외부 호출 금지. 알림은 commit 이후 큐로. 알림 실패가 장애 기록을 롤백하면 안 됩니다.
- 멱등성은 나중이 아니라 지금. 재시도 + 분산은 기본값이라고 가정하고, 중복 발송을 키 하나로 막아둡니다.
그리고 솔직한 한 줄: TASK-007에서 last_status를 성급하게 잡았다가 TASK-008에서 고쳤습니다. 빠르게 가다 보면 이런 게 생기는데, TASK 문서에 결정과 번복을 그대로 적어두니 다음 사람(=미래의 나)이 헷갈리지 않더군요.
이제 진짜로 URL이 죽으면 카톡이 옵니다. 다음은 이 모든 걸 사람이 보는 화면 — 대시보드와 히스토리(TASK-012)입니다.
goodtek은 vibePulse를 빌드인 퍼블릭으로 만들고 있습니다. 막히는 부분, 되돌린 선택, 별로였던 결정까지 그대로 기록합니다. 다음 글에서 또 만나요.