바이브 코딩을 체계적으로 하는 방법: AI 개발을 레일 위에 올리기


바이브 코딩으로 당장 돌아가는 프로그램을 만드는 건 예전보다 훨씬 쉬워졌습니다. Cursor AI를 켜고 만들고 싶은 화면이나 기능을 설명하면, 생각보다 빠르게 결과가 나옵니다.
처음에는 정말 신기합니다. “이 정도면 혼자서 SaaS 하나 만들 수 있겠는데?”라는 생각도 듭니다.
그런데 실제 서비스를 만들려고 하면 이야기가 조금 달라집니다. 돌아가는 프로그램을 만드는 것과, 고객에게 팔 수 있는 서비스를 계속 운영하는 것은 다릅니다.
저도 goodtek을 만들면서 이 부분을 계속 고민하게 됐습니다. AI로 코딩하면 속도는 빨라지지만, 그만큼 다른 문제가 생깁니다.
유지보수는 어떻게 할 것인가.
AI가 매번 같은 기준으로 개발하게 하려면 어떻게 해야 하는가.
채팅 기록이 사라졌을 때, 그동안의 결정과 맥락은 어디에 남길 것인가.
여러 기기에서 개발하거나, 나중에 팀원이 들어왔을 때 온보딩은 어떻게 할 것인가도 고민하게 됩니다. 이런 문제를 해결하지 못하면 바이브 코딩은 금방 블랙박스가 됩니다.
처음에는 빠르게 만들었는데, 어느 순간부터는 제가 만든 프로젝트인데도 왜 이렇게 되어 있는지 설명하기 어려워집니다.
그래서 저는 이번 goodtek 웹사이트 구축을 하나의 실험으로 삼아보려고 합니다. 그냥 AI에게 “만들어줘”라고 맡기는 게 아니라, AI가 따라야 할 레일을 먼저 만들고 그 위에서 개발해보는 방식입니다.
제가 생각하는 방향은 이렇습니다.
룰 + 스킬 + 문서 + Git 브랜치 정책으로 AI 개발을 레일 위에서 돌리고, 아키텍처가 바뀌면 문서도 함께 갱신한다.
이번 시리즈에서는 이 방법론으로 goodtek 웹사이트를 만들어보려고 합니다. goodtek은 이미 블로그, 커뮤니티, Notes를 갖추고 있습니다. 앞으로는 이들을 하나로 묶는 랜딩 페이지와, 향후 SaaS 앱들이 모이는 웹사이트를 만들 계획입니다.
저는 Cursor AI를 기준으로 설명하겠지만, 큰 구조는 Claude Code나 Codex CLI를 사용할 때도 크게 다르지 않다고 생각합니다. 도구는 달라도 결국 중요한 것은 비슷합니다.
AI가 읽을 수 있는 규칙이 있어야 하고, 작업 절차가 있어야 하고, 프로젝트 기억이 문서로 남아 있어야 합니다.
바이브 코딩을 하다 보면 생기는 문제
바이브 코딩의 가장 큰 장점은 속도입니다. 그런데 그 속도 때문에 문제가 생기기도 합니다.
기획이 덜 된 상태에서 바로 코딩을 시작합니다. 채팅창에서 결정한 내용이 문서로 남지 않습니다. 어느 날은 feature 브랜치를 만들고, 어느 날은 main에 바로 커밋합니다. 어떤 작업은 플랜을 짜고 시작하지만, 어떤 작업은 그냥 바로 고칩니다.
이렇게 몇 번 반복하면 프로젝트가 점점 흐려집니다. 처음에는 내가 주도하는 것 같았는데, 어느 순간부터는 AI가 만든 코드의 흐름을 따라가고 있는 느낌이 듭니다.
제가 느낀 문제는 대략 이런 것들입니다.
|
문제 |
왜 생기는가 |
|---|---|
|
무엇을 만들지 기준이 흔들림 |
채팅이 유일한 입력이 되기 때문 |
|
같은 작업을 매번 다르게 함 |
에이전트마다 컨텍스트가 다르기 때문 |
|
커밋과 결정의 연결이 끊김 |
왜 바꿨는지가 문서에 남지 않기 때문 |
|
팀 합류 시 온보딩이 어려움 |
코드만 있고 운영 기억이 없기 때문 |
|
범위 밖 기능이 계속 추가됨 |
MVP 경계가 AI에게 명확히 전달되지 않기 때문 |
이 문제를 한 문장으로 정리하면 이렇습니다.
채팅은 신뢰할 수 없습니다. Git에 있는 문서와 커밋이 진실이어야 합니다.
AI와 나눈 대화는 중요합니다. 하지만 채팅은 사라질 수 있습니다. 다른 기기에서는 안 보일 수도 있고, 세션이 바뀌면 맥락이 끊길 수도 있습니다.
그래서 저는 앞으로 goodtek 개발에서는 채팅을 최종 기록으로 보지 않으려고 합니다. 최종 기록은 Git 안에 있어야 합니다. 작업 단위는 문서로 남고, 결정은 decision log에 남고, 구현 결과는 commit과 PR에 남아야 합니다.
AI가 참조하는 구조
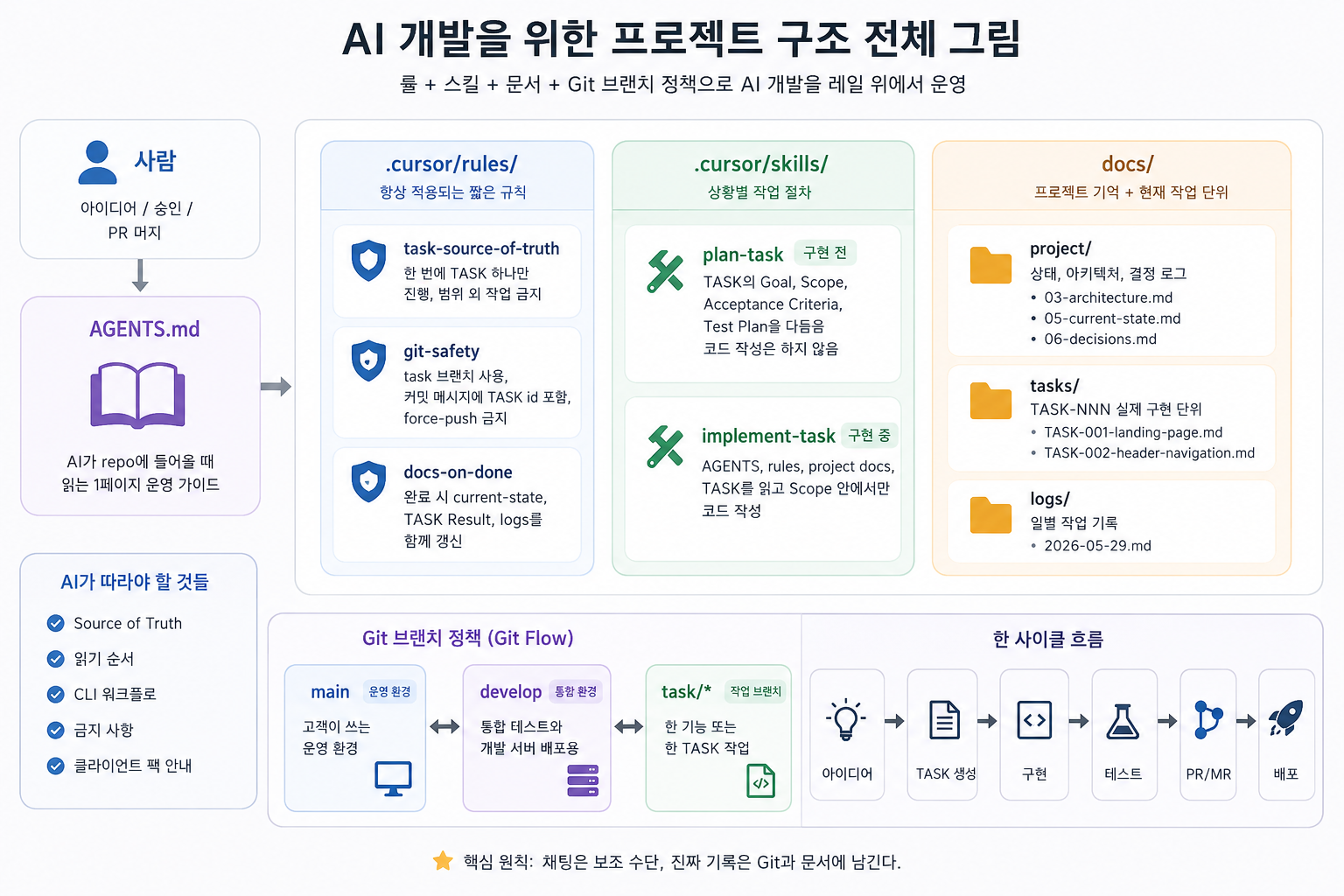
제가 생각하는 구조는 간단합니다. 사람은 아이디어를 내고, 방향을 승인하고, 마지막에 MR이나 PR을 머지합니다. AI는 코드를 작성하지만, 아무렇게나 작성하지 않습니다.
AI가 먼저 읽어야 할 문서가 있고, 항상 지켜야 할 규칙이 있고, 상황별 작업 절차가 있어야 합니다.
전체 그림은 이렇게 볼 수 있습니다.
[사람]
아이디어 / 승인 / PR 머지
│
▼
[AGENTS.md]
AI가 repo에 들어올 때 읽는 1페이지 운영 가이드
│
├── .cursor/rules/
│ 항상 적용되는 짧은 규칙
│
├── .cursor/skills/
│ 상황별 작업 절차
│
└── docs/
프로젝트 기억 + 현재 작업 단위
│
├── project/
│ 상태, 아키텍처, 결정 로그
│
├── tasks/
│ TASK-NNN 실제 구현 단위
│
└── logs/
일별 작업 기록AGENTS.md는 프로젝트 헌법이다
가장 먼저 필요한 것은 AGENTS.md입니다. 저는 이 파일을 프로젝트 헌법처럼 보고 있습니다.
Cursor Rules보다 더 넓은 개념입니다. 새로운 AI 세션이 열리거나, 다른 에이전트가 repo를 열었을 때 가장 먼저 읽어야 하는 문서입니다.
여기에는 아주 구체적인 코드 규칙보다, 프로젝트를 어떻게 다뤄야 하는지가 들어갑니다.
|
항목 |
내용 |
|---|---|
|
Source of Truth |
TASK, project docs, Git 중 무엇을 기준으로 삼을지 정리 |
|
코딩 전 읽기 순서 |
current-state → architecture → decisions → 현재 TASK |
|
CLI 워크플로 |
init → task add → plan/build → task done → status |
|
금지 사항 |
채팅만 보고 구현, TASK 밖 작업, docs 미갱신 후 완료 처리 금지 |
|
클라이언트 팩 |
Cursor, Claude Code, Codex별 rules / skills 위치 안내 |
AGENTS.md에는 너무 긴 설명을 넣지 않는 게 좋습니다. AI가 repo를 열 때마다 읽어야 하는 1페이지 운영 가이드라고 생각하면 됩니다.
상세한 작업 절차는 skills에 두고, 프로젝트 기억은 docs에 둡니다.
.cursor/rules는 하드 가드레일이다
그다음은 .cursor/rules/입니다. rules는 항상 적용되는 짧은 규칙입니다.
저는 각 rule을 길게 쓰지 않는 게 좋다고 봅니다. 한 파일이 50줄을 넘어가면 AI도 사람도 잘 안 읽게 됩니다.
rules에는 이런 것들을 넣습니다.
|
Rule |
역할 |
|---|---|
|
task-source-of-truth |
한 번에 TASK 하나만 진행하고, Scope와 Acceptance Criteria 밖 작업 금지 |
|
git-safety |
task 브랜치 사용, 커밋 메시지에 TASK id 포함, force-push 금지 |
|
docs-on-done |
완료 시 current-state, TASK Result, logs를 함께 갱신 |
rules는 매 대화마다 AI가 자동으로 지켜야 하는 기본 법입니다. 여기에는 철학보다 금지사항과 강제사항을 넣는 게 좋습니다.
예를 들어 이런 식입니다.
- 작업 전 반드시 현재 TASK 파일을 읽는다.
- TASK Scope 밖의 코드는 수정하지 않는다.
- main 브랜치에서 직접 작업하지 않는다.
- 완료 전 docs/project/05-current-state.md를 갱신한다.
- 커밋 메시지에는 TASK id를 포함한다.이 정도로 짧고 명확해야 합니다.
.cursor/skills는 작업 매뉴얼이다
rules가 항상 지켜야 할 법이라면, skills는 상황별 작업 절차입니다.
예를 들어 구현 전에 쓰는 skill과 실제 구현할 때 쓰는 skill은 달라야 합니다. 제가 기본으로 생각하는 skill은 두 개입니다.
|
Skill |
언제 사용 |
하는 일 |
|---|---|---|
|
plan-task |
구현 전 |
TASK 파일의 Goal, Scope, Acceptance Criteria, Test Plan을 다듬음. 코드 작성은 하지 않음 |
|
implement-task |
구현 중 |
AGENTS, rules, project docs, TASK를 읽고 Scope 안에서만 코드 작성 |
이 구분이 중요합니다.
AI에게 처음부터 “구현해줘”라고 하면 바로 코드를 고치기 시작합니다. 하지만 실제로는 구현 전에 먼저 TASK를 다듬어야 합니다.
Goal이 명확한지, Scope가 너무 넓지 않은지, Out of Scope가 있는지, Acceptance Criteria가 검증 가능한지 봐야 합니다.
그래서 Cursor에서도 역할을 나누는 게 좋습니다. Ask 모드에서는 plan-task를 사용하고, Agent 모드에서는 implement-task를 사용합니다.
간단히 말하면 이렇습니다.
Rules는 항상 지켜야 할 법이고, Skills는 지금 이 단계에서 따라야 할 절차입니다.
docs는 프로젝트 기억이다
마지막으로 가장 중요한 것이 docs/입니다.
AI 개발에서 문서가 중요한 이유는 단순합니다. 채팅은 사라질 수 있지만, repo 안의 문서는 남습니다.
저는 docs를 크게 세 부분으로 나누려고 합니다.
docs/
project/
03-architecture.md
05-current-state.md
06-decisions.md
tasks/
TASK-001-landing-page.md
TASK-002-header-navigation.md
logs/
2026-05-29.mddocs/tasks/는 실제 작업 단위입니다. 한 TASK는 하나의 PR 또는 MR이 됩니다.
이 원칙이 중요합니다. TASK가 너무 커지면 리뷰하기 어렵고, 너무 작으면 관리 비용이 커집니다. 일단은 “하나의 논리적 변경”을 하나의 TASK로 보는 게 좋습니다.
TASK 파일에는 이런 내용이 들어갑니다.
|
섹션 |
용도 |
|---|---|
|
Goal |
이 TASK가 끝나면 무엇이 가능해지는지 정의 |
|
Scope / Out of Scope |
AI가 건드릴 범위와 명시적으로 제외할 범위 |
|
Acceptance Criteria |
검증 가능한 완료 조건 |
|
Test Plan |
어떻게 확인할지 정리 |
|
Git Context |
브랜치명, base commit 등 |
|
Result / Test Result |
구현 후 실제 변경 경로, 명령, 결과 기록 |
docs/project/는 프로젝트 전체 기억입니다. 여기에는 지금 상태, 아키텍처, 결정 로그가 들어갑니다.
05-current-state.md는 TASK가 끝날 때마다 갱신합니다. 03-architecture.md는 구조가 바뀔 때만 갱신합니다. 06-decisions.md는 중요한 결정을 할 때마다 append합니다.
예를 들어 “왜 WordPress가 아니라 Ghost인가”, “왜 Discourse가 아니라 NodeBB인가” 같은 내용은 decisions에 남겨야 합니다. 나중에 기억이 흐려졌을 때, 이 파일이 프로젝트의 기억이 됩니다.
개발 워크플로: TASK 하나가 PR 하나다
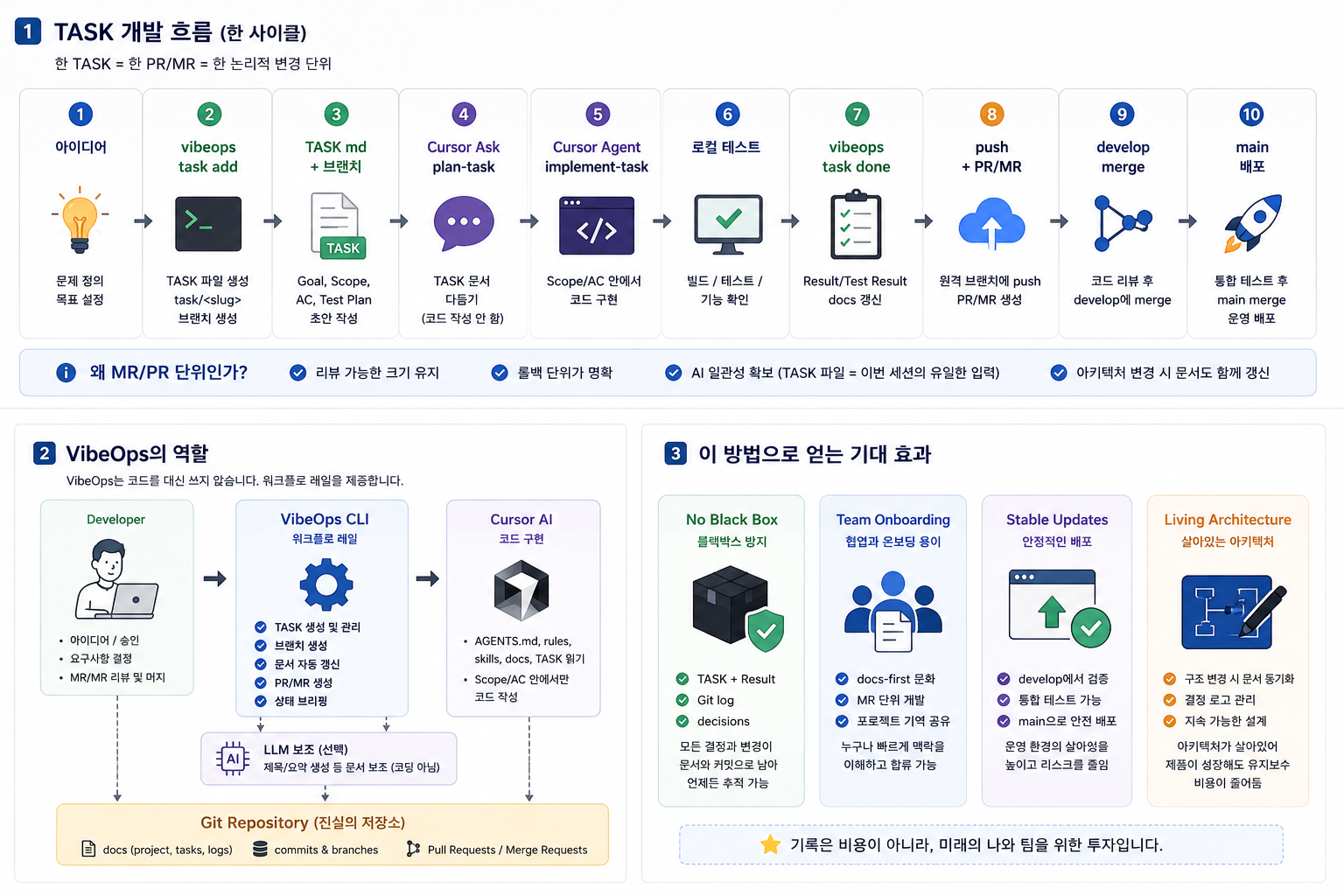
이제 실제 개발 흐름을 정리해보겠습니다.
저는 한 사이클을 이렇게 생각합니다.
아이디어
↓
vibeops task add
↓
TASK md + task 브랜치 생성
↓
Cursor Ask: plan-task
↓
Cursor Agent: implement-task
↓
로컬 테스트
↓
vibeops task done
↓
push + PR/MR 생성
↓
develop merge
↓
통합 테스트
↓
main merge + 배포여기서 핵심은 TASK입니다.
TASK는 이번 세션의 유일한 입력이어야 합니다. AI에게 너무 많은 이야기를 주면 범위가 흐려집니다. 반대로 TASK 파일이 명확하면 AI도 훨씬 안정적으로 움직입니다.
TASK는 PR/MR과 1:1로 맞추는 게 좋습니다. 왜냐하면 리뷰 가능한 크기를 유지할 수 있고, 문제가 생겼을 때 롤백 단위가 명확해지기 때문입니다.
아키텍처 변경이 들어간 TASK라면, 그 작업 안에서 03-architecture.md도 함께 갱신합니다. 즉, 코드만 바뀌는 게 아니라 프로젝트 기억도 같이 바뀌어야 합니다.
Git은 팀 협업용만이 아니다
여기서 Git 이야기를 꼭 해야 합니다.
많은 1인 개발자는 Git을 “팀 협업할 때 쓰는 것” 정도로 생각하기 쉽습니다. 저도 예전에는 그랬습니다.
하지만 AI와 개발할수록 Git은 더 중요해집니다.
AI 세션이 바뀌어도 커밋과 문서가 맥락을 유지해줍니다. 언제, 왜, 무엇이 바뀌었는지 사람과 AI가 같은 기준으로 볼 수 있습니다.
Git 명령어는 많고, 처음 보면 어렵습니다. 요즘은 옵션도 많고, 상황에 따라 쓰는 방식도 다양합니다.
하지만 처음부터 다 알 필요는 없다고 생각합니다. 앞으로만 가는 기본 흐름만 알아도 충분히 시작할 수 있습니다.
어려운 건 AI에게 물어보면서 진행하면 됩니다. 저도 그렇게 합니다.
Git 초보자용 비유: 내 책상과 팀 창고
Git을 어렵게 생각하면 끝이 없습니다. 저는 이렇게 비유하는 게 제일 편했습니다.
로컬은 내 책상입니다. 원격 저장소는 팀 창고입니다.
브랜치는 작업용 클립보드입니다.
commit은 봉투를 봉인하고 라벨을 붙이는 일입니다.
push는 그 봉투를 창고로 보내는 일입니다.
pull은 창고에서 최신 자료를 가져오는 일입니다.
PR이나 MR은 “이걸 합쳐도 될까요?”라고 요청하는 일입니다.
|
개념 |
비유 |
설명 |
|---|---|---|
|
로컬 |
내 책상 |
내 컴퓨터에서 작업하는 공간 |
|
원격 remote |
팀 창고 |
GitHub, GitLab 같은 클라우드 저장소 |
|
브랜치 |
작업용 클립보드 |
main, develop, task 브랜치가 각각 독립된 작업 줄 |
|
add |
서류를 봉투에 넣기 |
변경 파일을 커밋할 목록에 올림 |
|
commit |
봉투 봉인 + 라벨 |
이 시점의 스냅샷을 로컬에 확정 |
|
push |
창고로 보내기 |
로컬 커밋을 원격에 업로드 |
|
pull |
창고에서 최신 가져오기 |
원격 변경을 로컬에 반영 |
|
PR / MR |
합쳐도 될까요? 요청 |
리뷰 후 develop 또는 main에 merge |
중요한 점은 브랜치가 로컬에도 있고, 원격에도 있다는 것입니다.
내 컴퓨터에서 작업하고, commit으로 저장하고, push로 원격에 올립니다. 그다음 PR이나 MR을 만들어서 develop이나 main에 합칩니다.
develop과 main을 나누는 이유
저는 기본적으로 develop과 main을 나누는 흐름을 추천합니다.
main은 고객이 쓰는 운영 환경입니다. develop은 통합 테스트와 개발 서버 배포용입니다. task 브랜치는 한 기능이나 한 TASK를 작업하는 임시 브랜치입니다.
|
브랜치 |
역할 |
비유 |
|---|---|---|
|
main |
고객이 쓰는 운영 환경 |
출시된 제품 |
|
develop |
통합·스테이징 환경 |
QA실 / 시연장 |
|
task/* |
한 기능·한 TASK 작업 |
개인 초안 노트 |
가끔 이런 생각이 들 수 있습니다.
“혼자 개발하는데 develop이 왜 필요하지?”
저도 그렇게 생각했습니다.
하지만 실제 서비스를 만들다 보면 로컬만으로 테스트가 안 되는 경우가 있습니다. HTTPS나 SSL이 필요한 API가 있을 수 있습니다. OAuth 콜백처럼 실제 도메인이 필요한 기능도 있습니다.
운영과 비슷한 환경에서 통합 테스트를 해봐야 알 수 있는 문제도 있습니다. 그래서 develop은 운영 전에 검증하는 공간으로 두는 게 좋습니다. main은 develop에서 검증이 끝난 것만 올립니다.
실제 하루 작업 흐름
하루 작업은 이렇게 가져가면 됩니다.
develop에서 pull
↓
task/015-landing 브랜치 생성
↓
TASK 파일 보고 plan → 구현
↓
로컬 테스트
↓
add → commit
↓
push
↓
PR/MR 생성
↓
develop merge
↓
develop 환경에서 추가 테스트
↓
문제 없으면 develop → main merge
↓
고객 환경 배포커밋 메시지는 이런 식으로 통일합니다.
feat(task-015): add hero section
fix(task-016): resolve mobile menu issue
docs(task-017): update architecture notes처음에는 조금 번거롭게 느껴질 수 있습니다. 하지만 이 흐름이 쌓이면 나중에 AI에게도 설명하기 쉬워집니다.
“TASK-015에서 뭐 했는지 봐줘.”
이렇게 말하면 AI가 task 파일과 커밋을 함께 읽고 맥락을 복원할 수 있습니다.
@goodtek/vibeops라는 레일
이 과정을 매번 손으로 하기는 어렵습니다.
작업 파일 만들고, 브랜치 만들고, TASK 번호 붙이고, PR 본문 작성하고, docs 갱신하는 일을 사람이 계속 하다 보면 결국 빠뜨리게 됩니다.
그래서 저는 이 과정을 돕는 CLI를 생각하고 있습니다.
이름은 일단 @goodtek/vibeops로 잡아봤습니다.
VibeOps는 Cursor나 Claude Code, Codex가 코드를 쓰고, CLI가 파일과 Git, 문서 갱신, 짧은 LLM 보조를 맡는 워크플로 레일입니다.
중요한 점은 VibeOps가 코드를 대신 짜는 도구가 아니라는 것입니다. 코드는 Cursor가 작성합니다.
VibeOps는 TASK 생성, 브랜치 생성, 완료 처리, 문서 갱신, PR/MR 생성을 반복 가능하게 묶어주는 도구입니다.
VibeOps 핵심 명령
일상에서 필요한 명령은 많지 않습니다. 처음에는 4개면 충분하다고 생각합니다.
|
명령 |
하는 일 |
|---|---|
|
vibeops init |
AGENTS.md, rules, skills, docs 뼈대 설치 |
|
vibeops task add |
다음 TASK 파일과 task 브랜치 생성 |
|
vibeops task done |
Result, Test Result, project docs 갱신 후 push와 PR/MR 생성 |
|
vibeops status |
활성 TASK, 브랜치, docs 상태 브리핑 |
설치는 이런 식으로 생각하고 있습니다.
npm install -g @goodtek/vibeops초기화는 이렇게 할 수 있습니다.
vibeops init --clients cursor --git --initial-commit --git-policy gitflow그러면 이런 구조가 생깁니다.
AGENTS.md
.cursor/
rules/
skills/
docs/
tasks/
TASK-000-template.md
project/
03-architecture.md
05-current-state.md
06-decisions.md
logs/Git 정책은 .vibeops.json에 둡니다.
{
"integrationBranch": "develop",
"productionBranch": "main",
"taskBranchPrefix": "task",
"commitMessagePattern": "feat(task-{id}): {title}"
}이렇게 해두면 task add는 develop에서 task 브랜치를 만들고, task done은 push와 PR/MR 생성까지 도와줍니다.
로컬에서 바로 merge하지 않는 것이 중요합니다. merge는 사람이 확인하고 진행합니다.
VibeOps 없이도 가능하다
여기서 중요한 점이 있습니다.
VibeOps가 필수는 아닙니다.
같은 폴더 구조와 Git Flow, TASK 문서를 직접 운영해도 됩니다. 다만 매번 손으로 브랜치 이름을 만들고, TASK 문서를 만들고, PR 본문을 쓰고, current-state를 갱신하는 일이 귀찮을 뿐입니다.
VibeOps는 그 반복을 줄여주는 도구입니다.
즉, VibeOps의 역할은 “개발자 대신 생각하는 것”이 아닙니다. 개발자가 정한 흐름을 빠뜨리지 않게 도와주는 레일입니다.
Source of Truth를 명확히 해야 한다
AI 개발에서 가장 중요한 것은 무엇을 믿을 것인지 정하는 것입니다.
저는 이렇게 나누려고 합니다.
|
신뢰할 것 |
신뢰하지 않을 것 |
|---|---|
|
docs/tasks/*.md |
Cursor 채팅만의 기억 |
|
docs/project/*.md |
Slack이나 메신저에 흩어진 대화 |
|
Git commits / branches |
기억나는 대로 설명하는 것 |
|
PR / MR 기록 |
로컬에서만 남은 임시 변경 |
AI는 채팅을 잘 기억하는 것처럼 보일 때가 있습니다. 하지만 개발 운영에서는 그렇게 믿으면 위험합니다.
채팅은 보조 수단입니다. 진짜 기록은 repo 안에 있어야 합니다.
기대하는 효과
이 방식으로 개발하면 처음에는 조금 느려 보일 수 있습니다.
TASK도 써야 하고, 브랜치도 만들어야 하고, docs도 갱신해야 합니다. 하지만 장기적으로는 훨씬 안정적이라고 생각합니다.
AI 개발이 블랙박스가 되지 않습니다. TASK, Result, Git log, decisions가 남기 때문입니다.
나중에 팀원이 들어와도 온보딩이 가능해집니다. 코드만 보는 것이 아니라, 왜 이런 구조가 되었는지 문서로 볼 수 있습니다.
업데이트도 안정적으로 할 수 있습니다. develop에서 검증하고, main으로 배포하는 흐름을 만들 수 있기 때문입니다.
아키텍처도 살아 있게 됩니다. 구조가 바뀔 때 03-architecture.md를 같이 갱신하면, 문서와 코드가 따로 놀지 않게 됩니다.
이 방법은 아직 실험 중이다
물론 이 방법이 완벽하다고 생각하지는 않습니다. 오히려 아직 실험 중인 방법론에 가깝습니다.
너무 문서가 많아지면 귀찮아질 수 있습니다. 규칙이 너무 강하면 바이브 코딩의 속도가 죽을 수도 있습니다. 반대로 규칙이 너무 약하면 다시 블랙박스가 됩니다.
그래서 균형이 중요합니다.
goodtek에서는 이 균형을 실제 프로젝트를 만들면서 찾아보려고 합니다. 처음부터 완벽한 방법론을 선언하기보다는, 직접 부딪히면서 남길 생각입니다.
잘 되는 부분도 있을 것이고, 너무 과해서 버리는 부분도 있을 것입니다. 그 과정 자체가 goodtek의 기록이 될 수 있다고 생각합니다.
마무리
바이브 코딩은 분명 강력합니다. 하지만 실제 서비스를 만들려면 속도만으로는 부족합니다.
고객에게 팔 수 있는 서비스를 만들고, 계속 수정하고, 운영하고, 나중에 팀원이나 다른 AI 에이전트가 이어받을 수 있게 하려면 기록이 필요합니다.
저는 그 기록의 중심을 채팅이 아니라 Git과 문서에 두려고 합니다.
AGENTS.md는 프로젝트 헌법이 되고, rules는 하드 가드레일이 되고, skills는 작업 매뉴얼이 됩니다. docs는 프로젝트 기억이 되고, TASK는 PR/MR 하나의 단위가 됩니다.
그리고 VibeOps는 이 흐름을 매번 손으로 반복하지 않도록 도와주는 선택적 레일이 됩니다.
앞으로 goodtek 웹사이트를 만들면서 이 방식을 실제로 적용해보려고 합니다. 블로그, 커뮤니티, Notes, 그리고 향후 SaaS 앱들이 모이는 웹사이트를 TASK 단위로 만들어가며, 그 과정에서 겪는 시행착오도 함께 공유하겠습니다.
완벽한 방법을 소개하는 글은 아닙니다.
제가 실제로 겪고 있는 문제를 해결하기 위해 하나씩 만들어보는 기록입니다.
AI가 코드를 쓰는 시대에도, 결국 중요한 것은 사람이 어떤 기준으로 개발을 운영하느냐라고 생각합니다.
goodtek에서는 그 기준을 직접 만들어보려고 합니다.