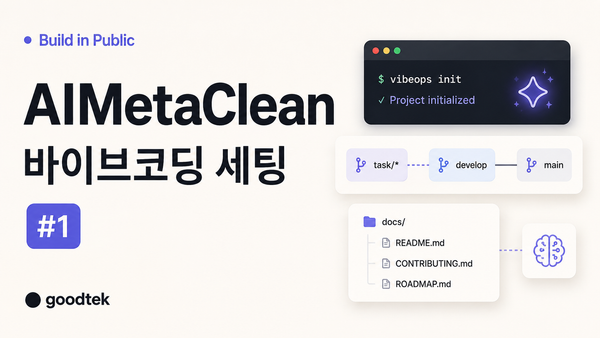
Build Log: TASK-001 모노레포 만들기
vibePulse의 첫 번째 실제 작업으로 TASK-001 모노레포를 구성했습니다. Next.js, NestJS, worker, Postgres/TimescaleDB, Redis, CI, /health 체크까지 한 번에 잡으면서 빠른 구현보다 먼저 기준을 세우는 것이 왜 중요한지 돌아봤습니다. 운영 DB 데이터 전략과 named volume에 대한 고민도 함께 정리했습니다.


이번 TASK-001은 vibePulse에서 처음으로 진행한 실제 작업이었습니다.
사용자가 보는 기능을 만든 것은 아니었습니다.
대시보드도 없었고, 인증도 없었고, 알림도 없었습니다. 모니터링 로직도 아직 없었습니다. 브라우저에 뜬 화면도 제품이라기보다는 스캐폴드에 가까웠습니다.
그런데도 이 작업은 중요했습니다.
앞으로 만들 기능들이 올라갈 첫 번째 바닥을 만드는 일이었기 때문입니다. 기능은 나중에 바뀔 수 있습니다. 하지만 프로젝트의 기본 구조가 흔들리면, 이후 모든 작업이 계속 영향을 받습니다.
처음에는 vibeops task add로 TASK-001을 만들었습니다.
그다음 /plan-task 스킬을 사용해서 로드맵에 있던 TASK-001 내용을 실제 작업 계획으로 바꾸게 했습니다.
이번에 한 일은 단순히 “모노레포 만들어줘”라고 Cursor에게 던지는 것이 아니었습니다.
먼저 계획을 만들게 했습니다.
그 계획이 로드맵과 맞는지 확인했습니다.
범위가 너무 넓어지지 않았는지 봤습니다.
그다음 구현을 맡겼습니다.
결과적으로 약 10분 만에 제가 원하던 기본 스택으로 모노레포가 구성됐습니다.
하지만 이번 작업에서 기억에 남은 것은 속도 자체가 아니었습니다.
빠르게 만든 것보다, 만들기 전에 기준을 먼저 세운 것이 더 중요했습니다.
이번 TASK-001의 핵심은 “빨리 만들었다”가 아니라, “어디까지 만들고 어디서 멈출지 먼저 정했다”에 가까웠습니다.
TASK-001에서 먼저 정한 기준
TASK-001의 목표는 명확했습니다.
한 명령으로 로컬 전체 스택이 떠야 한다.
web, api, worker가 각각 실행되어야 했습니다.
Postgres/TimescaleDB와 Redis도 함께 떠야 했습니다.
그리고 각 앱은 /health로 살아 있는지 확인할 수 있어야 했습니다.
이 목표를 기준으로 작업 범위를 먼저 나눴습니다.
|
영역 |
이번에 한 일 |
아직 하지 않은 일 |
|---|---|---|
|
web |
Next.js 16 App Router 스캐폴드, |
실제 제품 UI |
|
api |
NestJS 11 부트스트랩, |
도메인 API |
|
worker |
NestJS 기반 worker, |
BullMQ 실제 연결 |
|
infra |
Postgres/TimescaleDB, Redis compose 구성 |
운영 배포 |
|
tooling |
pnpm workspace, ESLint, Prettier, TS 설정 |
테스트 고도화 |
|
CI |
install / lint / build 게이트 |
CD 파이프라인 |
여기서 일부러 선을 그었습니다.
TASK-001은 기능 개발 작업이 아니었습니다.
프로젝트 골격을 만드는 작업이었습니다.
그래서 인증, 모니터링 도메인, DB 마이그레이션, 큐 연결, 배포 자동화는 이번 범위에서 제외했습니다.
처음부터 모든 것을 연결하고 싶은 마음은 있었습니다.
인증도 붙이고 싶었고, queue도 연결하고 싶었고, 운영 compose도 미리 만들어두고 싶었습니다.
하지만 그렇게 하면 첫 번째 작업부터 너무 무거워집니다.
무엇보다 나중에 문제가 생겼을 때, 어디서 꼬였는지 보기 어려워집니다.
이번에는 그 욕심을 줄이는 것이 중요했습니다.
TASK-001은 제품을 완성하는 작업이 아니라, 앞으로 제품을 만들 수 있는 상태를 만드는 작업이었습니다.
바로 구현하지 않은 이유
이번 작업은 Cursor에게 바로 구현을 맡기지 않았습니다.
먼저 vibeops task add로 실제 작업 파일을 만들었습니다.
그다음 /plan-task로 작업 계획을 만들게 했습니다.
그리고 그 계획을 사람이 다시 봤습니다.
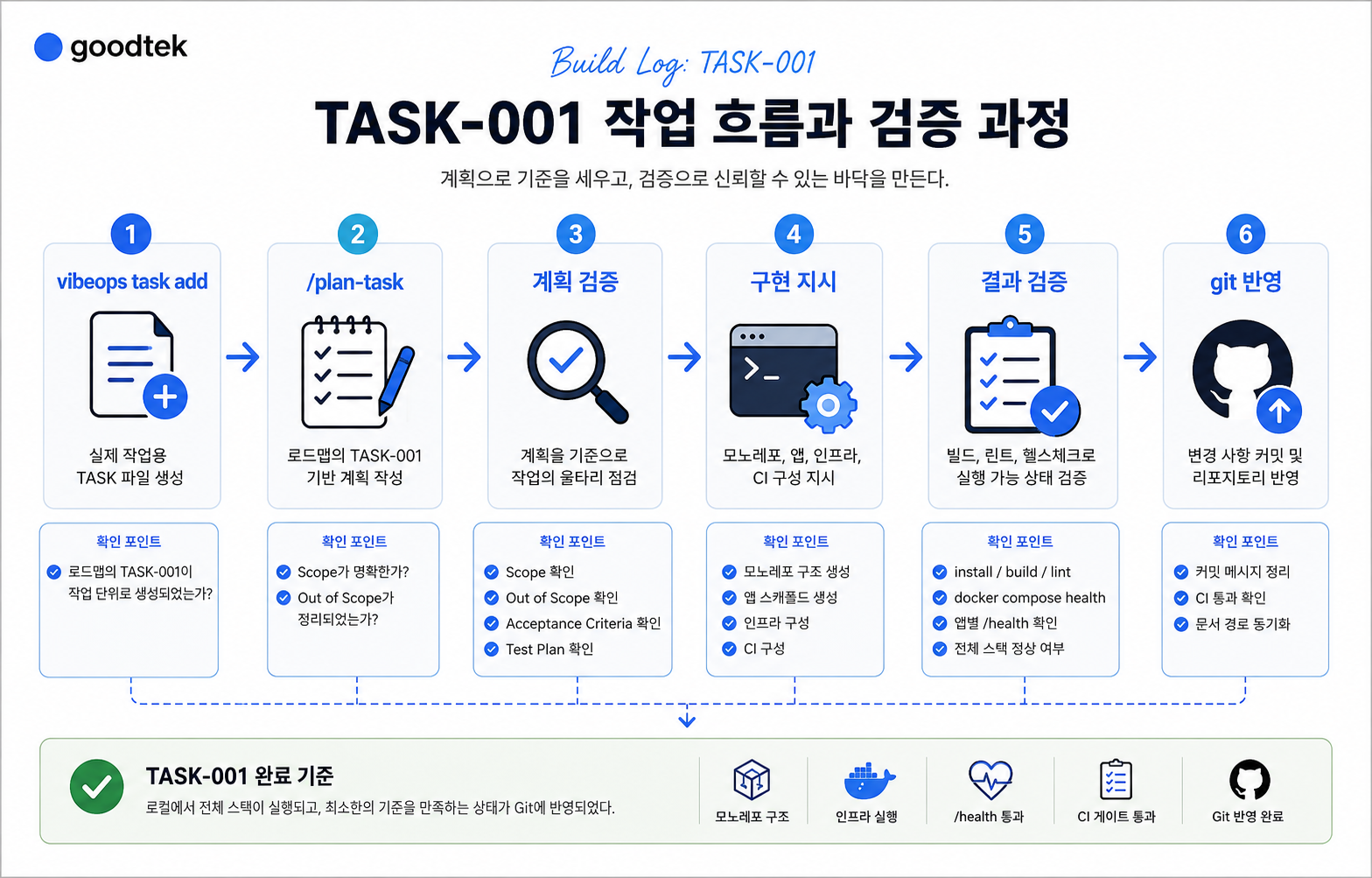
흐름은 이렇게 정리할 수 있습니다.
TASK-001 진행 흐름
├─ vibeops task add
│ └─ 실제 작업용 TASK 파일 생성
├─ /plan-task
│ └─ 로드맵의 TASK-001 기반 계획 작성
├─ 계획 검증
│ ├─ Scope 확인
│ ├─ Out of Scope 확인
│ ├─ Acceptance Criteria 확인
│ └─ Test Plan 확인
├─ 구현 지시
│ └─ 모노레포, 앱, 인프라, CI 구성
└─ 결과 검증
├─ install
├─ build
├─ lint
├─ docker compose health
└─ 앱별 /health 확인이 순서가 꽤 중요했습니다.
AI에게 바로 구현을 맡기면 빠릅니다.
하지만 빠른 만큼 범위가 쉽게 흔들립니다.
“이것도 해둘까요?”
“이 부분도 미리 붙여둘까요?”
“운영용 설정도 같이 만들까요?”
이런 식으로 작업이 커지면, 처음 정한 태스크의 경계가 흐려집니다.
반대로 먼저 계획을 세워두면 구현 중에도 계속 기준점으로 돌아갈 수 있습니다.
이번에는 /plan-task가 그 기준점 역할을 했습니다.
로드맵에 적힌 TASK-001을 실제 작업 단위로 바꾸고, 해야 할 일과 하지 않을 일을 분리했습니다.
AI에게 일을 맡기되, 기준은 사람이 확인하는 방식으로 진행했습니다.
이번 TASK-001에서 가장 잘한 부분은 구현 속도를 높인 것이 아니라, 구현 전에 작업의 울타리를 먼저 친 것이었습니다.
10분 만에 잡힌 기본 구조
구현 결과, 기본 구조는 빠르게 잡혔습니다.
vibepulse
├─ apps
│ ├─ web
│ │ └─ Next.js 16 App Router
│ ├─ api
│ │ └─ NestJS 11
│ └─ worker
│ └─ NestJS standalone + health
├─ packages
│ ├─ shared
│ └─ sdk
├─ docs
│ ├─ plan
│ ├─ project
│ └─ tasks
├─ scripts
│ └─ infisical-run.sh
├─ compose.yaml
└─ .github
└─ workflows
└─ ci.yml루트에는 pnpm workspace 설정을 넣었습니다.
Node 버전은 22 LTS 기준으로 맞췄고, pnpm 버전도 package manager로 고정했습니다.
앱은 세 개로 나눴습니다.
web은 Next.js 16 App Router, TypeScript, Tailwind 4 기반으로 구성했습니다.
api는 NestJS 11로 최소 부트스트랩을 만들었습니다.
worker도 NestJS 기반으로 만들되, 아직 실제 queue 처리는 연결하지 않았습니다.
각 앱에는 /health를 붙였습니다.
GET /health
{
"status": "ok",
"service": "web"
}api와 worker도 같은 방식으로 응답하게 했습니다.
이 endpoint는 단순한 확인용처럼 보일 수 있습니다.
하지만 이후 배포와 모니터링에서는 계속 기준점이 됩니다.
특히 worker에 /health를 붙인 점이 좋았습니다.
worker는 일반적인 HTTP 서버처럼 보이지 않을 수 있습니다. 하지만 운영 관점에서는 살아 있는지 확인할 수 있는 표면이 필요합니다.
보이지 않는 프로세스도 운영에서는 확인 가능한 형태로 만들어야 합니다.
pnpm dev 하나로 시작되는 로컬 환경
이번 작업에서 중요하게 본 기준 중 하나는 로컬 실행 경험이었습니다.
개발을 시작할 때마다 명령어를 여러 개 기억하고 싶지 않았습니다.
Postgres 따로 띄우고, Redis 따로 띄우고, api 따로 실행하고, worker 따로 실행하고, web 따로 실행하는 방식이면 금방 흐트러집니다.
그래서 목표는 단순했습니다.
pnpm dev 하나로 로컬 개발에 필요한 스택이 함께 떠야 한다.
구성은 이렇게 잡았습니다.
|
명령 |
역할 |
|---|---|
|
pnpm dev |
로컬 인프라와 앱 실행 |
|
pnpm build |
워크스페이스 전체 빌드 |
|
pnpm lint |
전체 lint 확인 |
|
pnpm infra:up |
Postgres/Redis 실행 |
|
pnpm infra:down |
로컬 인프라 종료 |
시크릿은 Infisical을 기준으로 두었습니다.
다만 로컬에서는 .env fallback도 가능하게 했습니다. 그래서 scripts/infisical-run.sh를 추가했습니다.
여기서 신경 쓴 것은 균형이었습니다.
처음부터 운영 환경을 과하게 흉내 내고 싶지는 않았습니다.
하지만 나중에 운영 방식으로 넘어갈 수 있는 길까지 막고 싶지도 않았습니다.
처음에는 단순해야 합니다.
그런데 나중에 완전히 갈아엎어야 할 정도로 단순하면 안 됩니다.
이 경계가 생각보다 중요했습니다.
3000 포트에 뜬 첫 화면
구성이 끝난 뒤 pnpm dev로 스택을 띄웠습니다.
그리고 브라우저에서 3000 포트를 열었습니다.
아직 제품이라고 부를 만한 화면은 아니었습니다.
하지만 Next.js 앱이 올라왔고, health route도 응답했습니다. api와 worker도 각각 살아 있는지 확인할 수 있었습니다.
확인 결과는 이렇게 정리됐습니다.
|
확인 항목 |
결과 |
|---|---|
|
pnpm install |
성공 |
|
pnpm build |
성공 |
|
pnpm lint |
성공 |
|
Postgres/TimescaleDB |
healthy |
|
Redis |
healthy |
|
web /health |
200 |
|
api /health |
200 |
|
worker /health |
200 |
여기까지는 꽤 깔끔했습니다.
“좋습니다. 이제 첫 번째 태스크는 닫아도 되겠습니다.”
그런데 마지막으로 다시 보던 중에 하나가 걸렸습니다.
여기서 걸린 named volume
문제는 DB 데이터가 Docker의 named volume에 잡혀 있었다는 점이었습니다.
로컬 개발에서는 named volume이 나쁜 선택이 아닙니다.
오히려 편합니다. 이름만 지정하면 Docker가 알아서 관리해주고, compose 파일도 단순해집니다.
예를 들면 이런 식입니다.
services:
postgres:
volumes:
- pgdata:/var/lib/postgresql/data
volumes:
pgdata:로컬에서는 충분히 괜찮습니다.
하지만 운영을 생각하면 이야기가 달라집니다.
운영 DB 데이터가 named volume에 들어가면, 실제 데이터가 호스트 어디에 있는지 운영자가 명확히 의식하지 못할 수 있습니다. Docker가 관리하는 내부 경로에 저장되고, 백업이나 디스크 분리, 마이그레이션, 복구 리허설을 설계할 때 확인해야 할 것이 늘어납니다.
문제의 핵심은 성능이 아니었습니다.
named volume이 느려서 문제가 아니라, 운영 데이터의 위치와 생명주기가 앱 배포와 섞일 수 있다는 점이 걸렸습니다.
그래서 여기서 잠깐 멈췄습니다.
그리고 운영 기준을 다시 봤습니다.
|
구분 |
named volume |
bind mount |
|---|---|---|
|
로컬 개발 |
편하고 충분함 |
조금 번거로움 |
|
운영 데이터 위치 |
Docker 관리 경로 |
사람이 정한 명시 경로 |
|
백업 설계 |
위치 확인 필요 |
경로 기준으로 명확 |
|
디스크 분리 |
상대적으로 덜 명시적 |
별도 디스크 마운트에 유리 |
|
실수 방지 |
볼륨 삭제 위험 인지 필요 |
운영 경로로 의식하기 쉬움 |
결론은 명확했습니다.
로컬 개발은 named volume을 써도 괜찮습니다.
하지만 운영 DB 데이터는 명시 경로에 두는 쪽이 더 낫다고 판단했습니다.
예를 들면 이런 구조입니다.
/srv/vibepulse
├─ pgdata
├─ redis
└─ backups이렇게 두면 운영자가 데이터 위치를 더 명확히 의식하게 됩니다.
백업도 경로 기준으로 잡을 수 있고, 디스크 분리나 복구 리허설도 더 명확해집니다.
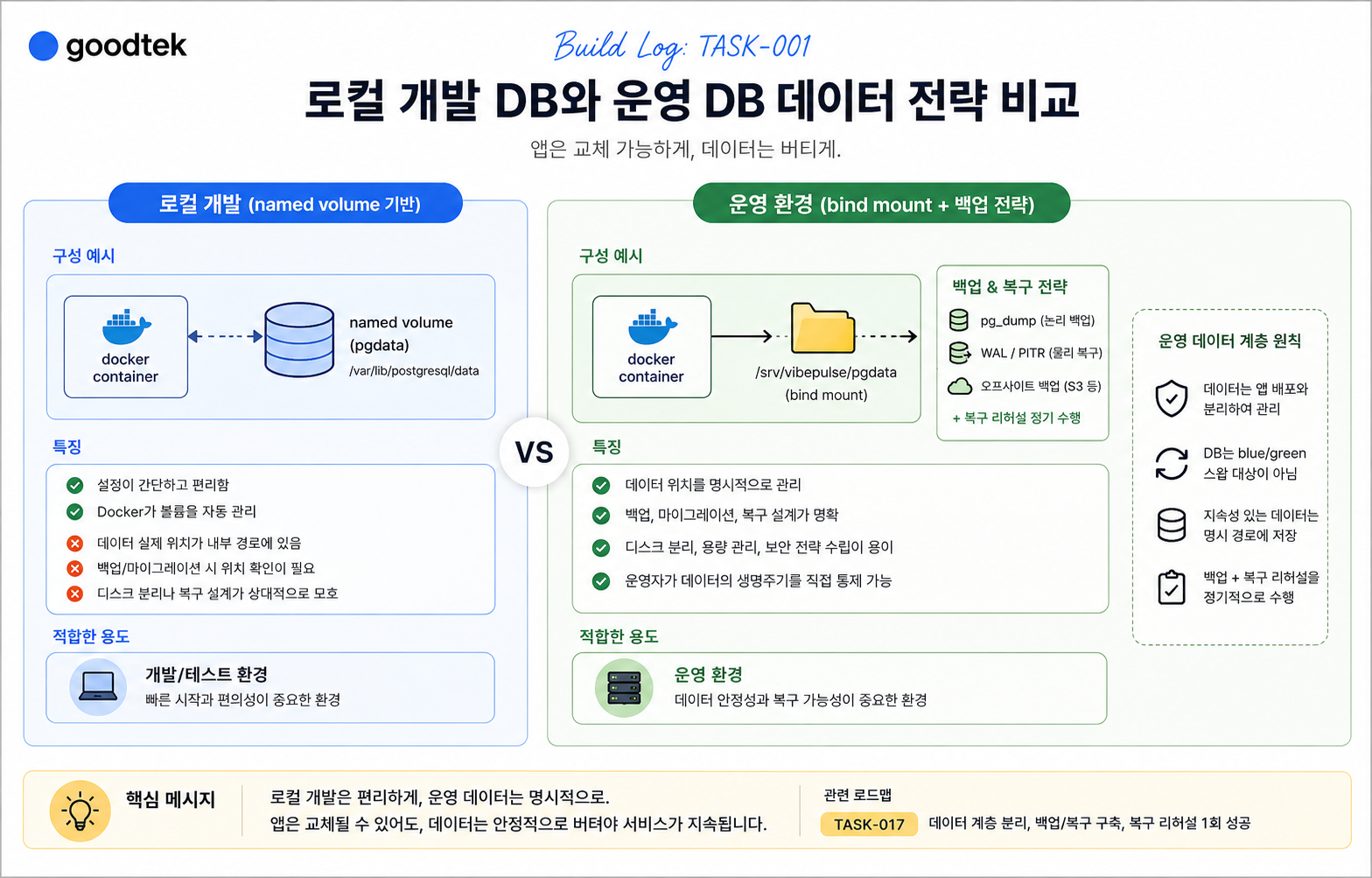
앱은 바뀌어도 데이터는 버텨야 합니다
여기서 더 중요한 기준이 하나 생겼습니다.
DB는 blue/green 배포의 스왑 대상이 아니어야 한다.
앱은 교체될 수 있습니다.
새 버전이 올라오고, 문제가 생기면 이전 버전으로 롤백할 수 있습니다. web, api, worker는 배포 슬롯 단위로 바뀔 수 있습니다.
하지만 DB 컨테이너와 데이터까지 앱 슬롯과 함께 교체되면 위험해집니다.
운영에서는 앱과 데이터의 라이프사이클을 분리해야 합니다.
운영 배포 기준
├─ 교체 가능
│ ├─ web
│ ├─ api
│ └─ worker
└─ 교체 대상 아님
├─ postgres
├─ redis
└─ persistent data이 기준을 문서에 반영했습니다.
01-architecture-and-stack.md에는 프로덕션 데이터 계층을 추가했습니다.03-decisions.md에는 PD-35로 결정 사항을 남겼습니다.02-roadmap.md의 TASK-017에는 데이터 계층 분리, 백업, 복구 리허설을 Scope와 Acceptance Criteria에 추가했습니다.
중요한 점은 이번 TASK-001에서 운영 compose나 백업 스크립트를 바로 만들지 않았다는 것입니다.
그건 TASK-017에서 할 일입니다.
이번에는 지금 발견한 찝찝함을 그냥 넘기지 않고, 나중에 구현할 태스크의 기준으로 먼저 남겼습니다.
지금 고칠 것과 나중에 제대로 구현할 것을 분리한 것이 이번 작업의 중요한 판단이었습니다.
바로 구현하지 않은 것도 결정입니다
이 문제를 발견했을 때 바로 운영용 compose를 만들고 싶었습니다.
compose.prod.yaml을 만들고, backup script를 붙이고, S3 같은 offsite 저장소까지 연결하고, 복구 명령어도 미리 만들어두고 싶었습니다.
그런데 그렇게 하면 TASK-001이 아닙니다.
이번 작업의 목적은 모노레포 부트스트랩입니다.
운영 데이터 전략을 실제로 구현하는 작업은 별도 태스크에서 다뤄야 합니다.
그래서 이번에는 문서와 로드맵에 기준을 반영하는 선에서 멈췄습니다.
|
문제 |
이번에 한 조치 |
실제 구현 시점 |
|---|---|---|
|
운영 DB 데이터가 named volume에 의존할 수 있음 |
운영은 bind mount 기준으로 문서화 |
TASK-017 |
|
DB가 앱 배포 라이프사이클과 섞일 위험 |
DB는 blue/green 스왑 제외로 결정 |
TASK-017 |
|
백업 기준이 약함 |
pg_dump + WAL/PITR + 오프사이트 백업 반영 |
TASK-017 |
|
복구 검증이 빠질 수 있음 |
Acceptance에 복구 리허설 1회 성공 추가 |
TASK-017 |
이 판단이 마음에 들었습니다.
예전 같으면 여기서 작업이 계속 커졌을 것입니다.
모노레포를 만들다가 운영 배포를 만들고, 운영 배포를 만들다가 백업 전략을 만들고, 백업 전략을 만들다가 모니터링까지 손댔을지도 모릅니다.
하지만 그렇게 하면 첫 번째 태스크는 끝나지 않습니다.
이번에는 기준을 이렇게 잡았습니다.
- 지금은 모노레포를 만듭니다
- 지금은 로컬 개발 스택을 확인합니다
- 지금은
/health와 CI 게이트를 만듭니다 - 운영 데이터 전략은 문서와 로드맵에 반영합니다
- 실제 운영 구현은 TASK-017에서 합니다
이 선을 지킨 것이 꽤 중요했습니다.
하지 않는 것도 작업의 일부였습니다.
Git에 남긴 첫 번째 바닥
검증이 끝난 뒤 변경 사항은 git에 반영했습니다.
브랜드 표기도 함께 정리했습니다.
문서와 코드에 남아 있던 VibePulse 표기를 vibePulse로 통일했습니다.
다만 환경변수명인 VIBEPULSE_URL은 그대로 두었습니다.
환경변수는 대문자 컨벤션을 따르는 것이 맞기 때문입니다.
이런 작은 정리도 초반에 해두는 것이 좋습니다.
나중에 브랜드명, 패키지명, 도메인, 환경변수가 뒤섞이면 수정 비용이 커집니다.
이번 TASK-001의 결과는 이렇게 남았습니다.
- pnpm workspace 기반 모노레포 구성
- web/api/worker 앱 스캐폴드 생성
- 각 앱
/health확인 - Postgres/TimescaleDB, Redis 로컬 compose 구성
- Infisical 실행 래퍼 추가
- CI install/lint/build 구성
- 문서 구조와 실제 경로 동기화
- 운영 DB 전략을 로드맵에 반영
- git 반영 완료
겉으로 보면 첫 화면 하나 띄운 작업입니다.
하지만 실제로는 vibePulse가 앞으로 어떤 방식으로 커질지에 대한 첫 번째 기준을 만든 작업이었습니다.
TASK-001을 닫기 전에 본 체크리스트
이번 작업을 닫기 전에 다시 확인한 기준은 이렇습니다.
- 한 명령으로 로컬 개발 스택을 띄울 수 있는가
- web, api, worker가 각각 실행되는가
- 각 앱이
/health로 상태를 알려주는가 - Postgres/TimescaleDB와 Redis가 healthy 상태인가
- install, lint, build가 CI에서 확인 가능한가
- 이번 작업의 Scope를 넘지 않았는가
- 지금 발견한 운영 이슈가 다음 태스크에 반영됐는가
- 나중에 다시 봐도 왜 이렇게 했는지 문서에서 확인할 수 있는가
마지막 항목이 특히 중요했습니다.
빠르게 만드는 일은 AI가 도와줄 수 있습니다.
하지만 나중에 다시 봤을 때 “왜 이 구조였지?”를 이해할 수 있게 남기는 일은 결국 사람이 챙겨야 합니다.
이번 TASK-001은 그런 의미에서 단순한 초기 세팅이 아니었습니다.
AI에게 맡길 수 있는 일과 사람이 기준을 잡아야 하는 일의 경계를 확인한 작업이었습니다.
다음은 두 번째 태스크입니다
이제 TASK-001은 닫을 수 있을 것 같습니다.
3000 포트에 스캐폴드가 떴습니다.
health check가 통과했습니다.
git에도 반영됐습니다.
로컬에서 작업을 이어갈 수 있는 기본 바닥이 생겼습니다.
다음은 두 번째 태스크입니다.
아직 속도를 크게 내기보다, 이번처럼 차근차근 확인하면서 진행하려고 합니다.
AI에게 맡길 수 있는 것은 맡기되, 기준과 경계는 계속 직접 확인하면서 갈 생각입니다.
빠르게 만드는 것보다 중요한 것은, 나중에 다시 봐도 왜 이렇게 만들었는지 이해할 수 있는 상태로 남기는 것입니다.
● goodtek은 이 과정을 계속 Build Log로 남겨보려고 합니다.
완성된 제품보다, 제품이 만들어지는 중간의 판단들이 더 오래 남을 때가 많기 때문입니다.