vibeops init 이후, 코딩보다 먼저 정한 것들
vibeops init으로 프로젝트 골격을 만들고, LLM과 티키타카하며 VibePulse의 아키텍처, 기술 스택, UX, 알림 구조, 데이터 보존 전략, TASK 단위 로드맵을 먼저 정리한 과정입니다. 코딩을 시작하기 전에 AI에게 맡길 것과 사람이 통제할 기준을 어떻게 나눴는지 기록했습니다.


솔직히 프로젝트를 시작할 때 제일 먼저 하고 싶은 건 코드입니다.
빈 화면에 뭔가 뜨고, API가 응답하고, 대시보드 비슷한 게 생기면 “아, 이제 시작했구나” 싶은 기분이 듭니다.
그런데 이번 VibePulse 프로젝트에서는 일부러 그 순서를 조금 늦췄습니다.
코드를 쓰기 전에 먼저 한 일은 이것이었습니다.
프로젝트가 어떻게 굴러가야 하는지 정리하는 것.
AI가 어디까지 도와주고, 사람은 어디서 멈춰서 확인할지 정하는 것.
나중에 “이거 왜 이렇게 만들었지?”라고 묻게 될 지점을 미리 문서로 남기는 것.
이번에는 vibeops init으로 프로젝트 폴더를 초기화했습니다.
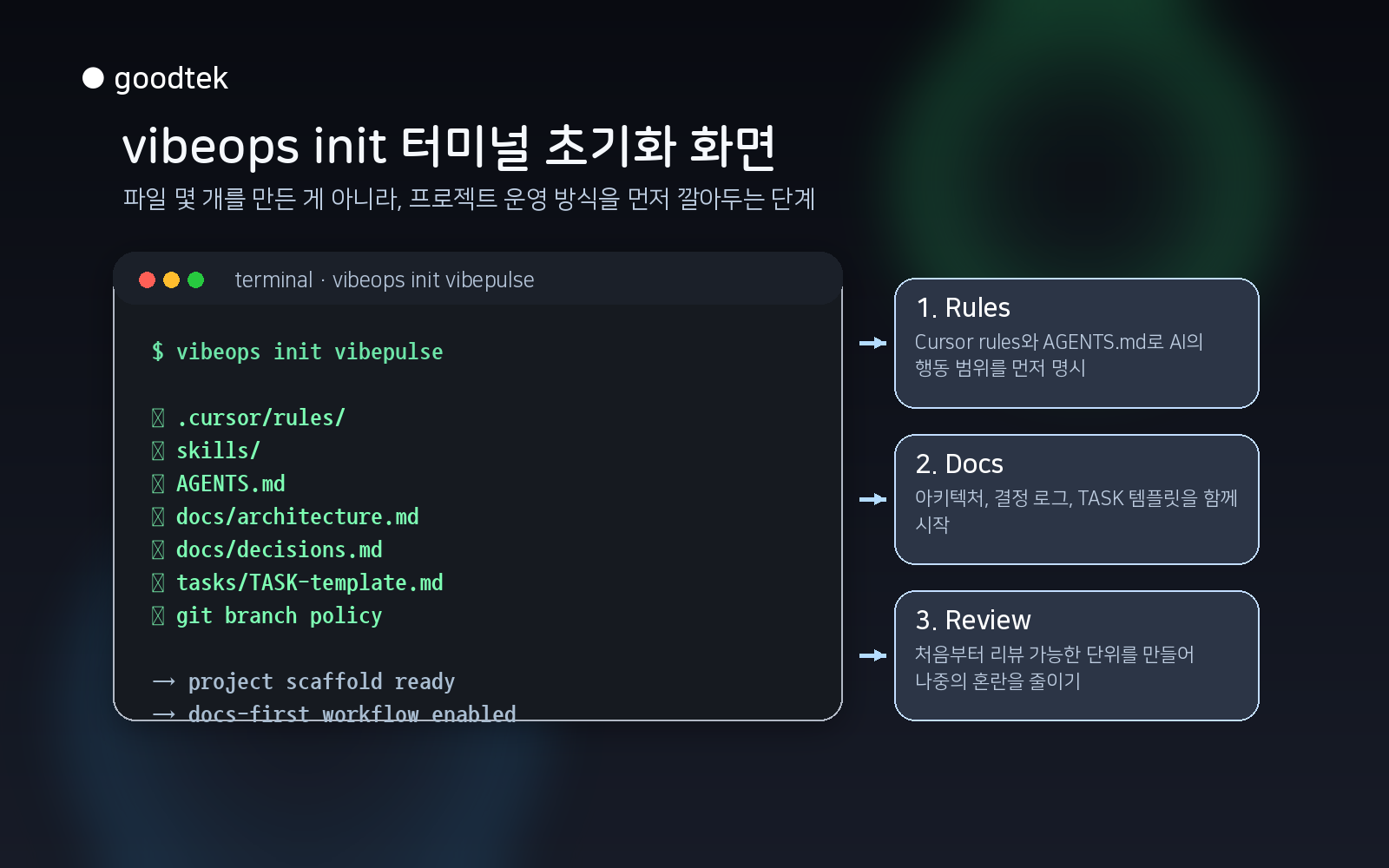
vibeops init으로 프로젝트 폴더를 초기화터미널에 생성된 파일 목록을 보면 단순한 초기 세팅처럼 보입니다.
Cursor rules, skills, AGENTS.md, docs, TASK 템플릿, git 브랜치 정책.
그런데 이번에 제가 진짜로 만들고 싶었던 건 파일 몇 개가 아니었습니다.
AI와 함께 개발해도 프로젝트가 블랙박스가 되지 않는 운영 방식이었습니다.
첫 코드를 미룬 이유
VibePulse는 한 줄로 말하면 바이브코더를 위한 초간단 서비스 생존 확인 SaaS입니다.
내가 만든 웹사이트나 API가 지금 살아 있는지 확인하고, 죽으면 바로 알려주는 서비스입니다.
처음에는 굉장히 단순해 보였습니다.
“URL 하나 저장하고 주기적으로 찔러보면 되는 거 아닌가?”
그런데 막상 구조를 잡기 시작하니 바로 질문이 늘어났습니다.
- 체크는 API 서버가 직접 해야 할까, worker가 따로 해야 할까
- 결과는 일반 테이블에 계속 쌓아도 될까
- Heartbeat처럼 5초마다 들어오는 신호는 전부 저장해야 할까
- 알림은 incident 처리 중에 바로 보내도 될까
- 사용자가 앱을 여러 개 운영하면 무엇으로 구분해야 할까
- Free, Pro, Team 같은 플랜은 나중에 붙여도 괜찮을까
여기서 잠깐 멈추게 됐습니다.
작게 시작하는 것과 대충 시작하는 건 다릅니다.
저는 이번 프로젝트에서 작게 시작하되, 나중에 갈아엎을 가능성이 큰 뼈대는 먼저 잡고 싶었습니다.
그래서 VibePulse는 MVP라고 해도 처음부터 아래 기준을 갖고 출발하기로 했습니다.
| 위험 지점 | 대충 시작하면 생기는 일 | 이번에 잡은 방향 |
|---|---|---|
| 체크 실행 | API 서버 안에서 임시 스케줄 실행 | worker + queue 분리 |
| 체크 결과 | 일반 테이블에 무한 INSERT | TimescaleDB + retention + rollup |
| 사용자 구조 | user 하나에 monitor 여러 개 | Org → Project → Monitor |
| 알림 | Email이나 Slack을 코드에 직접 연결 | 채널 추상화 + notification queue |
| 타입 계약 | 프론트/API/SDK가 각자 타입 관리 | packages/shared zod 단일 계약 |
| 수익화 | 나중에 Stripe만 붙이기 | Plan/Quota 모델 day 1 설계 |
이 표만 보면 약간 무겁게 느껴질 수 있습니다.
하지만 모니터링 제품은 “나중에”가 꽤 위험합니다.
체크 결과 저장 방식, 알림 발송 방식, 테넌시 구조는 기능이 조금만 쌓여도 바꾸기 어려워집니다.
이번에는 그 지점을 초반에 피하고 싶었습니다.
vibeops init이 만든 안전장치
vibeops init을 실행하면 기본적으로 프로젝트 운영을 위한 골격이 생깁니다.
이번 초기화에서 만들어진 구조는 대략 이렇습니다.
vibepulse
├── .cursor
│ ├── rules
│ └── skills
├── docs
│ ├── logs
│ ├── project
│ └── tasks
├── AGENTS.md
├── .vibeops.json
└── .gitignore
여기서 마음에 들었던 부분은 .cursor/rules와 .cursor/skills가 같이 생긴다는 점이었습니다.
LLM에게 매번 “이 프로젝트는 이렇게 작업해줘”라고 설명하는 대신, 프로젝트 안에 규칙을 박아둘 수 있습니다.
그리고 plan-task, implement-task 같은 흐름으로 계획과 구현을 분리할 수 있습니다.
이번 작업의 기준은 단순합니다.
AI에게 코딩은 많이 맡기되, 작업 단위와 완료 기준은 사람이 잡는다.
이게 없으면 바이브 코딩은 정말 빠릅니다.
그런데 어느 순간부터 내가 만든 서비스가 아니라, AI가 만들어놓은 결과물을 제가 따라가며 해석하는 느낌이 됩니다.
그건 피하고 싶었습니다.
인터뷰하듯 계획 문서를 만든 흐름
이번에 재미있었던 부분은 계획 문서를 한 번에 만들지 않았다는 점입니다.
LLM에게 “VibePulse 아키텍처 만들어줘”라고 던지지 않았습니다.
대신 인터뷰형 메타 프롬프트를 만들고, 단계별로 질문하게 했습니다.
0. 제품 정의
1. 스택과 인프라 제약
2. 인증
3. 수익화
4. 사용자 경험
5. 알림/통지
6. 데이터 보존과 이력
7. UI/UX 원칙
8. 도메인 전략
핵심은 “한 번에 다 묻지 말 것”이었습니다.
각 단계에서 LLM은 질문을 2~4개만 던지고, 제가 애매하게 답하면 합리적인 기본값과 이유를 제안하게 했습니다.
그리고 결정이 나면 관련 문서에 반영하고, 모순이 생기면 같이 수정하게 했습니다.
이 방식이 좋았던 이유는 명확합니다.
좋은 아키텍처는 답변 하나로 나오는 게 아니라, 질문이 쌓이면서 생깁니다.
처음에는 제품 정의에서 시작했습니다.
VibePulse의 방향은 화려한 관측성 플랫폼이 아닙니다.
로그, 트레이스, 메트릭을 전부 다루는 거대한 도구가 아니라, 훨씬 좁은 문제에 집중합니다.
“내 서비스가 죽었는지 바로 안다.”
이 한 문장입니다.
작게 만들지만, 제품이 커질 때 발목 잡을 구조는 피한다.
이번 계획 문서 전체가 사실 이 문장을 기준으로 정리됐습니다.
스택은 새로움보다 운영 경험을 우선
기술 스택을 정할 때도 새로워 보이는 조합을 고르지 않았습니다.
goodtek-web에서 이미 검증한 기반을 재사용하고, VibePulse에 필요한 요소만 추가하기로 했습니다.
| 레이어 | 선택 | 이유 |
|---|---|---|
| 프론트 | Next.js 16, TypeScript, Tailwind 4 | 마케팅, 대시보드, 상태페이지를 한 앱에서 운영 |
| API | NestJS 11 | 인증, CRUD, Heartbeat 인제스트, OpenAPI에 적합 |
| Worker | NestJS standalone + BullMQ | 프로브와 알림을 API 응답성과 분리 |
| DB | PostgreSQL 18 + TimescaleDB | 관계형 데이터와 시계열 체크 결과를 함께 처리 |
| Queue/Cache | Redis | BullMQ repeatable job, rate limit, lock |
| Auth | Better Auth | Google/GitHub/Kakao/Naver + organization |
| Payment | Stripe | Phase 3에서 Checkout, Billing Portal, Webhook |
| Contract | zod in packages/shared | DTO, SDK, 프론트 타입을 단일화 |
| Deploy | GHCR + Blue/Green + Caddy | goodtek-web 배포 패턴 재사용 |
여기서 가장 중요한 선택은 API와 worker를 분리한 것입니다.
API 서버가 사용자의 요청을 처리하는 동안, worker는 주기적으로 외부 URL을 찌르고 결과를 저장합니다.
알림도 incident 처리 과정에서 직접 보내지 않고, notifications 큐를 거치게 했습니다.
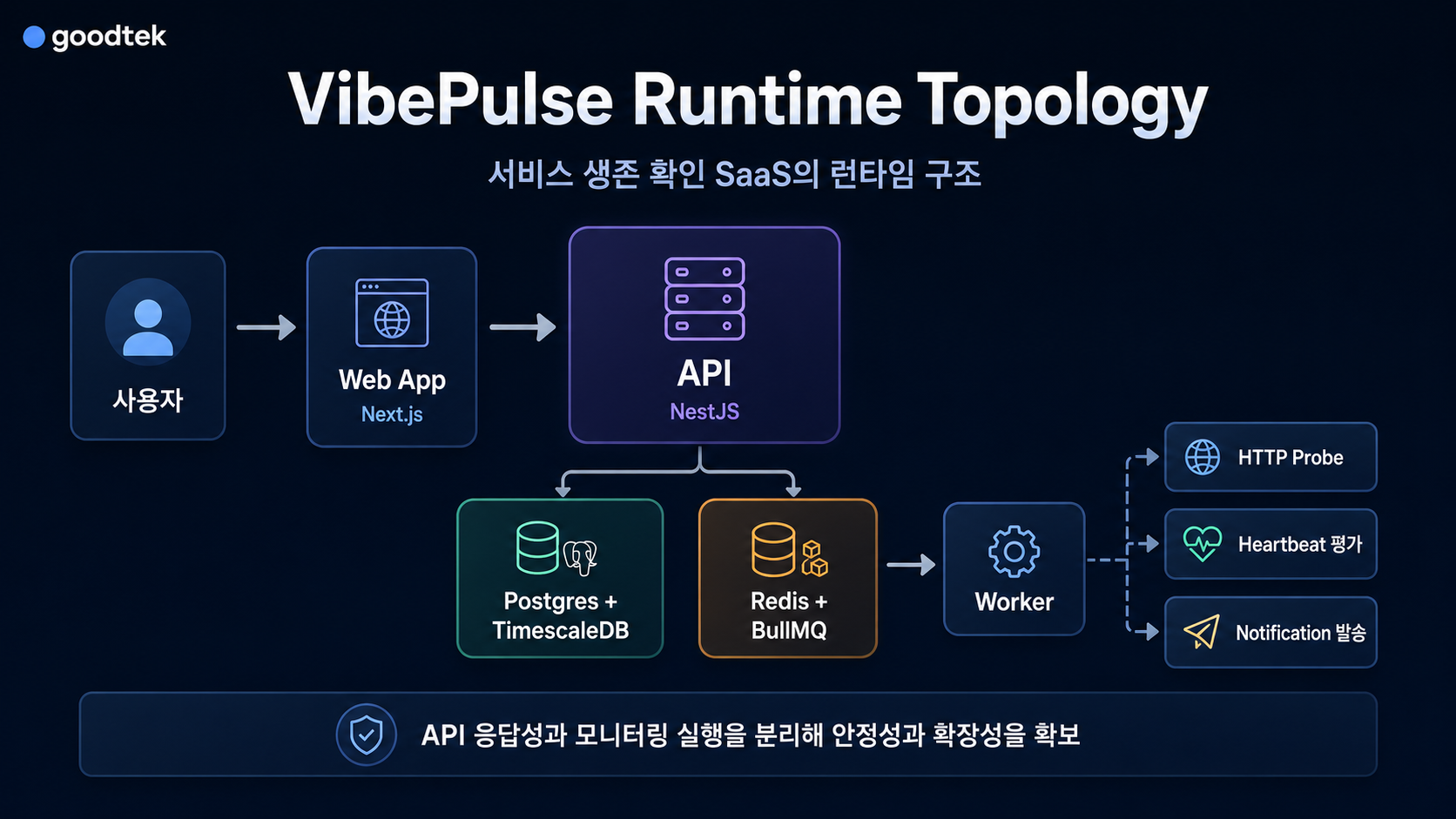
대략적인 런타임 흐름은 이렇게 잡았습니다.
사용자
└─ web (Next.js)
└─ api (NestJS)
├─ Postgres + TimescaleDB
└─ Redis + BullMQ
└─ worker
├─ HTTP probe
├─ heartbeat 평가
└─ notification 발송
이 구조의 장점은 단순합니다.
체크 대상이 많아져도 API 응답성이 바로 흔들리지 않습니다.
알림 채널 하나가 느리거나 실패해도 incident 판단 흐름을 막지 않습니다.
나중에 worker만 늘리는 방식으로 확장할 여지도 생깁니다.
데이터 모델에서 제일 먼저 고정한 것
VibePulse의 사용자 구조는 처음부터 Org → Project → Monitor로 잡았습니다.
처음에는 1인 개발자가 자기 앱 하나를 등록하는 그림만 생각할 수도 있습니다.
하지만 goodtek이 만들고 있는 SaaS들은 앞으로 여러 프로젝트를 동시에 운영하게 될 가능성이 큽니다.
그래서 “앱 구분”을 시크릿이나 API 키로 하지 않고, Project로 분리하기로 했습니다.
Org
├── Project A = myapp.com
│ ├── Monitor: 웹
│ ├── Monitor: API /health
│ └── Monitor: nightly-cron
├── Project B = otherapp.io
│ └── Monitor: 웹
└── Project C
이렇게 하면 대시보드, 공개 상태 페이지, 알림 채널 기본값, API 키를 프로젝트 단위로 나눌 수 있습니다.
다만 1인 사용자가 처음 가입했을 때부터 “Org와 Project를 이해하세요”라고 하면 부담스럽습니다.
그래서 가입 직후에는 Default 프로젝트를 자동으로 만들고, 사용자는 그냥 첫 URL만 넣게 하는 방향으로 잡았습니다.
복잡한 구조는 내부에 두고, 첫 경험은 단순하게.
이게 이번 UX 문서에서 계속 반복된 기준입니다.
URL, Ping URL, API Key를 분리한 이유
사용자가 서비스를 등록하는 방식은 세 가지로 나눴습니다.
| 방식 | 사용자가 등록하는 것 | 시크릿 필요 | 코드 필요 | 잡고 싶은 것 |
|---|---|---|---|---|
| URL 모니터링 | URL, 주기, 타임아웃 | 없음 | 없음 | 외부에서 접근 가능한 웹/API |
| Heartbeat | 자동 발급된 Ping URL | 없음 | 선택 | cron, worker, 내부 작업 |
| SDK/API | 프로젝트 API 키 | 필요 | 필요 | 프로그래밍 연동, 다중 모니터 |
기본 경로는 무조건 URL 모니터링입니다.
사용자는 URL 하나만 넣고, 즉시 1회 체크 결과를 봅니다.
첫 체크가 성공하면 대시보드에서 녹색 PulseIndicator와 “정상” 상태를 봅니다.
이게 첫 성공 경험입니다.
Heartbeat는 cron이나 worker처럼 외부에서 직접 찌르기 어려운 작업을 위한 방식입니다.
여기서는 API 키를 요구하지 않고, 모니터별 ping_token으로 만들어진 Ping URL을 제공합니다.
Project A / nightly-cron
└─ https://vibepulse.goodtek.xyz/ping/2f9a...c1
Project B / worker
└─ https://vibepulse.goodtek.xyz/ping/8be4...77
사용자는 작업이 끝난 뒤 이 Ping URL을 한 번 호출하면 됩니다.
API 키 발급, 보관, 회전 같은 부담을 초반 UX에서 제거할 수 있습니다.
SDK/API는 나중에 개발자용 연동 화면에서 제공합니다.
여기에는 프로젝트 API 키와 AI 설치 프롬프트를 함께 넣을 계획입니다.
이 부분은 VibePulse의 차별점과도 연결됩니다.
AI에게 그대로 시킬 수 있는 설치 경험.
사용자가 복붙하면 Cursor나 다른 코딩 에이전트가 현재 프로젝트에 맞게 SDK 연동을 해주는 흐름입니다.
알림은 간단하게 보이되, 내부는 큐로
알림 UX도 꽤 오래 고민했습니다.
처음에는 Email만 보내면 충분하지 않을까 싶었습니다.
하지만 실제로 서비스를 운영하다 보면 Email만으로는 부족합니다.
개인 프로젝트는 Telegram이 편할 수 있고, 팀은 Slack이나 Discord가 편할 수 있습니다.
Webhook을 열어두면 Zapier, n8n, Make 같은 자동화 도구와도 연결할 수 있습니다.
그래서 알림은 3단계로 나눴습니다.
| 단계 | 대상 | 제공 방식 |
|---|---|---|
| MVP | 대부분의 개인 사용자 | Email 기본, Discord/Slack/Telegram/Webhook |
| Pro | 여러 채널을 쓰는 사용자 | 알림 그룹, Org/Project 공유 채널 |
| Team | 팀 운영 | admin 또는 멤버 전원 알림 |
중요한 건 UI를 처음부터 복잡하게 만들지 않는 것입니다.
예를 들어 Telegram “모니터링 채널”과 “에러 채널”을 구분하고 싶을 수 있습니다.
이때 별도의 “채널 유형” UI를 만들지 않기로 했습니다.
그냥 이름이 다른 Telegram 채널 레코드 2개를 만들면 됩니다.
Telegram — 모니터링 채널
Telegram — 에러 채널
Discord alerts
Slack #alerts
내 이메일
그리고 모니터마다 받을 채널을 체크합니다.
내부 발송 로직은 단순한 듯하지만 중요한 기준이 있습니다.
incident open/resolved
└─ channels_to_notify 계산
└─ 중복 제거
└─ 채널별 NotificationJob enqueue
└─ notifications worker 발송
├─ retry + backoff
├─ DLQ
├─ timeout
└─ notification_log 기록
incident 처리 루프에서 webhook이나 Email을 직접 호출하지 않는다.
이 기준을 초반에 고정했습니다.
알림은 항상 큐를 거칩니다.
덕분에 어떤 채널이 느려도 incident 판단 흐름은 막히지 않습니다.
실패한 알림은 재시도할 수 있고, 최종 실패도 notification_log에 남길 수 있습니다.
Kafka는 도입하지 않기로 했습니다.
지금 단계에서 Kafka는 문제 해결보다 운영 복잡도를 더 키울 가능성이 큽니다.
월 수백만 알림, 다중 downstream, replay, 감사 요구가 생기기 전까지는 BullMQ로 충분하다고 판단했습니다.
데이터 보존은 처음부터 현실적으로
이번 문서 작업에서 가장 마음에 남은 부분은 데이터 보존이었습니다.
모니터링 제품은 이력을 보여줘야 합니다.
사용자는 90일 가동률, 지연 추세, 장애 타임라인, 알림 이력을 보고 싶어 합니다.
그런데 모든 신호를 원본 그대로 저장하면 금방 문제가 생깁니다.
예를 들어 5초 하트비트가 500개 모니터에서 들어오면 초당 100행입니다.
하루로 보면 약 860만 행입니다.
“일단 INSERT하고 나중에 생각하자”는 선택은 여기서는 꽤 위험합니다.
그래서 데이터는 계층형으로 저장하기로 했습니다.
| 계층 | 저장 대상 | 쓰기 방식 | 보존 | 용도 |
|---|---|---|---|---|
| 현재 상태 | monitors.last_* | UPDATE | 영구 | 목록/상세의 지금 상태 |
| 원본 체크 | check_results | INSERT | 짧게 | 최근 디버깅 |
| 롤업 | check_results_1m/1h/1d | continuous aggregate | 길게 | 가동률/지연 차트 |
| 상태 변화 | incidents | 희소 INSERT | 장기 | 장애 타임라인 |
| 알림 이력 | notification_log | 발송당 1행 | 플랜별 | 디버깅/재발송 근거 |
핵심은 이겁니다.
차트와 가동률은 원본에서 읽지 않는다.
원본은 짧게 보관하고, 장기 이력은 롤업에서 읽습니다.
Heartbeat도 ping마다 원본을 INSERT하지 않기로 했습니다.
성공 ping은 last_ping_at을 UPDATE하고, check_results에는 분당 최대 1행만 다운샘플링합니다.
작은 결정처럼 보이지만, 나중에 서버 비용과 운영 안정성에 큰 차이를 만들 수 있는 부분입니다.
UI의 기준은 “2초 안에 안심”
UI/UX 문서에서는 VibePulse의 노스스타를 이렇게 잡았습니다.
2초 안에 “다 정상이야” 또는 “여기가 문제야”를 보여준다.
이 문장이 꽤 마음에 들었습니다.
모니터링 제품의 UI는 예뻐 보이는 것보다 먼저 해야 할 일이 있습니다.
사용자의 불안을 줄여야 합니다.
정상일 때는 조용하고 차분해야 합니다.
장애일 때만 시선을 끌어야 합니다.
빨강은 정말 장애일 때만 써야 합니다.
상태는 다섯 가지로 고정했습니다.
| 상태 | 의미 | 라벨 |
|---|---|---|
| operational | 정상 | 정상 / Operational |
| degraded | 느림 | 느림 / Degraded |
| down | 장애 | 장애 / Down |
| paused | 일시정지 | 일시정지 / Paused |
| pending | 확인 중 | 확인 중 / Checking |
색만으로 상태를 표현하지 않는 것도 기준으로 넣었습니다.
상태는 색, 아이콘, 텍스트를 함께 사용합니다.
대시보드의 첫 화면은 이런 구조를 목표로 합니다.
StatusHero + PulseIndicator
└─ 모든 서비스 정상
5개 모니터 · 마지막 확인 12초 전
myapp.com ● 정상 99.2% 240ms
API /health ● 정상 100% 45ms
nightly-cron ● 정상 2분 전 ping
[+ 모니터 추가]
거창한 차트보다 먼저 보여줄 것은 “살아 있는가”입니다.
상세 화면으로 들어가면 90일 상태바, 지연 차트, 장애 타임라인, 연결된 알림 채널을 보여줍니다.
대시보드 = 살아있나.
상세 = 왜, 언제 문제가 있었나.
이력 = 추세가 어떤가.
이렇게 화면마다 질문을 하나씩만 맡기기로 했습니다.
로드맵은 TASK = PR 단위로 자르기
계획 문서를 만든 뒤 바로 전체 구현으로 들어가지 않습니다.
로드맵은 Phase 0부터 Phase 3까지 나눴고, 각 항목은 vibeops task add로 TASK를 생성해 진행합니다.
기준은 1 TASK = 1 PR입니다.
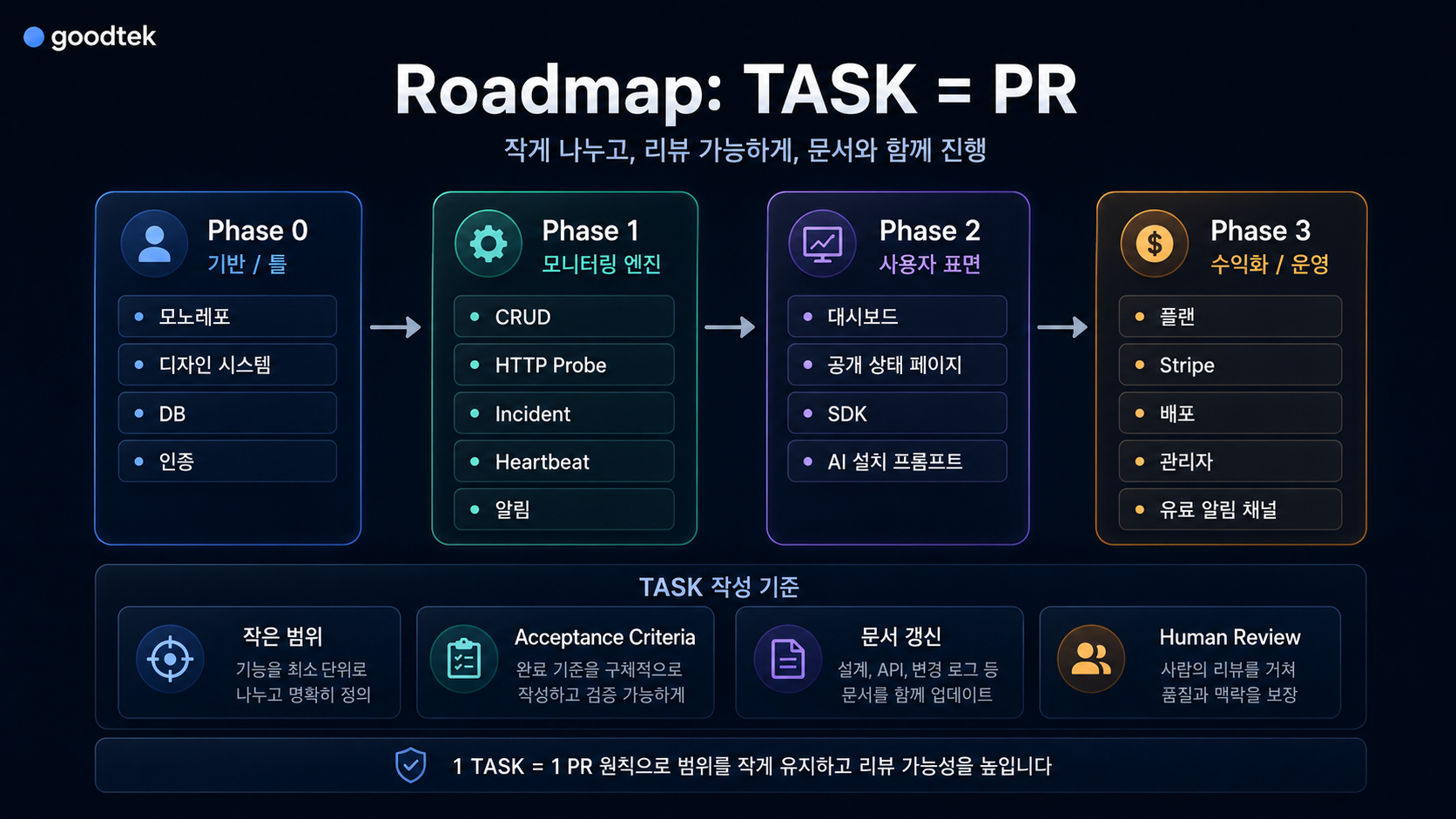
현재 로드맵은 이렇게 잡혀 있습니다.
| Phase | 목표 | 주요 TASK |
|---|---|---|
| Phase 0 | 기반/틀 | 모노레포, 디자인 시스템, DB, 인증 |
| Phase 1 | 모니터링 엔진 | CRUD, HTTP probe, incident, heartbeat, 알림 |
| Phase 2 | 사용자 표면 | 대시보드, 공개 상태 페이지, SDK, AI 설치 프롬프트 |
| Phase 3 | 수익화/운영 | 플랜, Stripe, 배포, 관리자, 유료 알림 채널 |
여기서 중요한 건 TASK 제목보다 Scope와 Acceptance Criteria입니다.
TASK를 만들 때마다 아래 질문을 확인하려고 합니다.
- 이번 TASK의 범위가 PR 하나로 리뷰 가능한가
- 이번 TASK에서 하지 않을 것도 명확한가
- 완료 기준이 실행 또는 화면으로 확인 가능한가
- 문서와 결정 로그가 같이 갱신되는가
- AI가 만든 결과를 사람이 멈춰서 검토할 지점이 있는가
이 기준이 없으면 AI에게 “계속 만들어줘”라고 하기 쉽습니다.
그러면 속도는 빠른데, 어느 순간부터 리뷰할 수 없는 덩어리가 생깁니다.
이번에는 그걸 피하고 싶습니다.
AI가 만든 것과 사람이 정한 것
이번 계획 작업을 하면서 느낀 건, AI를 잘 쓰려면 오히려 사람이 더 명확해야 한다는 점입니다.
AI는 구조를 제안할 수 있습니다.
비교표를 만들 수 있습니다.
놓친 질문을 던질 수 있습니다.
문서 간 모순을 찾아줄 수도 있습니다.
하지만 최종 기준은 사람이 정해야 합니다.
| 영역 | AI에게 맡긴 것 | 사람이 정한 것 |
|---|---|---|
| 아키텍처 초안 | 후보 구조 제안, 장단점 비교 | API/worker 분리, BullMQ 선택 |
| 제품 정의 | 문장 정리, 차별점 구조화 | “죽으면 바로 안다”에 집중 |
| UX | 온보딩 흐름 제안 | URL 모니터링을 기본 경로로 확정 |
| 알림 | 채널/그룹/팀 모델 정리 | Kafka 제외, 큐 기반으로 시작 |
| 데이터 보존 | 계층형 저장 방식 제안 | ping마다 INSERT 금지 |
| 로드맵 | TASK 분해 | 1 TASK = 1 PR 기준 |
이 균형이 중요하다고 느꼈습니다.
AI에게 전부 맡기면 빠르지만 불안합니다.
사람이 전부 하려면 느립니다.
그래서 이번 goodtek의 방식은 중간입니다.
AI는 빠르게 넓게 펼치고, 사람은 기준을 세워 좁힌다.
이번 빌드 로그에서 공개하는 것
Build in Public이라고 하면서 너무 좋은 말만 쓰면 재미가 없습니다.
그래서 이번 VibePulse는 가능한 한 실제 내용을 공개하려고 합니다.
시크릿, 개인 계정, 실제 키, 민감한 운영 정보가 아니라면 아키텍처, 스택, 로드맵, 결정 로그, UX 원칙까지 공개할 생각입니다.
이번 글에 공개한 내용도 실제 계획 문서에서 나온 것입니다.
- Next.js 16 + NestJS 11 + PostgreSQL 18 + TimescaleDB
- Redis + BullMQ 기반 worker/queue 구조
- Better Auth 기반 Google/GitHub/Kakao/Naver 로그인
- Org → Project → Monitor 멀티테넌시
- Ping URL과 API Key의 역할 분리
- Email, Discord, Slack, Telegram, Webhook 알림
- notification queue, retry, DLQ, idempotency
- check_results 원본 짧게, rollup 길게
- StatusHero, PulseIndicator, UptimeBar 중심 UI
- Phase 0~3 TASK/PR 로드맵
물론 이 계획이 전부 맞을 거라고 생각하지는 않습니다.
실제로 구현하다 보면 바뀔 겁니다.
어떤 TASK는 너무 커서 쪼개야 할 수 있고, 어떤 결정은 생각보다 복잡해서 뒤로 미뤄야 할 수도 있습니다.
처음 고른 스택의 일부가 실제 운영에서 불편할 수도 있습니다.
그래도 괜찮습니다.
중요한 건 바뀌지 않는 계획이 아니라, 왜 바뀌었는지 남는 과정입니다.
이제 진짜 TASK로 들어가기 전에
이번 단계는 아직 제품 기능을 만든 단계가 아닙니다.
대시보드도 아직 없고, 알림도 아직 안 갑니다.
사용자가 URL을 등록할 수도 없습니다.
하지만 저는 이 단계가 꽤 중요하다고 생각합니다.
vibeops init으로 프로젝트 운영의 골격을 만들고,
LLM과 인터뷰하듯 아키텍처와 스택을 정리하고,
로드맵을 TASK/PR 단위로 나누고,
나중에 흔들릴 수 있는 결정들을 문서에 남겼습니다.
이제 다음 작업은 TASK-001 · 모노레포 부트스트랩입니다.
목표는 단순합니다.
한 명령으로 web, api, worker, postgres, redis가 로컬에서 뜨는 것.
그리고 각 앱의 /health가 정상 응답하는 것.
작아 보이지만, 이게 VibePulse의 첫 번째 실제 바닥입니다.
다음 글에서는 아마 이 기준이 바로 시험대에 오를 것 같습니다.
계획 문서에서는 깔끔했던 것들이 실제 레포 안에서 얼마나 덜컹거리는지, 그 과정까지 그대로 남겨보겠습니다.