운영 서버에 배포 버튼을 누르기 전에 정한 것: 유료 회원에게 404를 보여주지 않기 위해
운영 서버 배포는 새 코드를 올리는 일이 아니라, 사용자의 접속을 끊지 않고 시스템을 교체하는 일입니다. goodtek이 유료 회원에게 404를 보여주지 않기 위해 Blue/Green 배포, Caddy upstream 전환, health check, 실제 끊김 테스트까지 구축하고 검증한 과정을 정리했습니다.

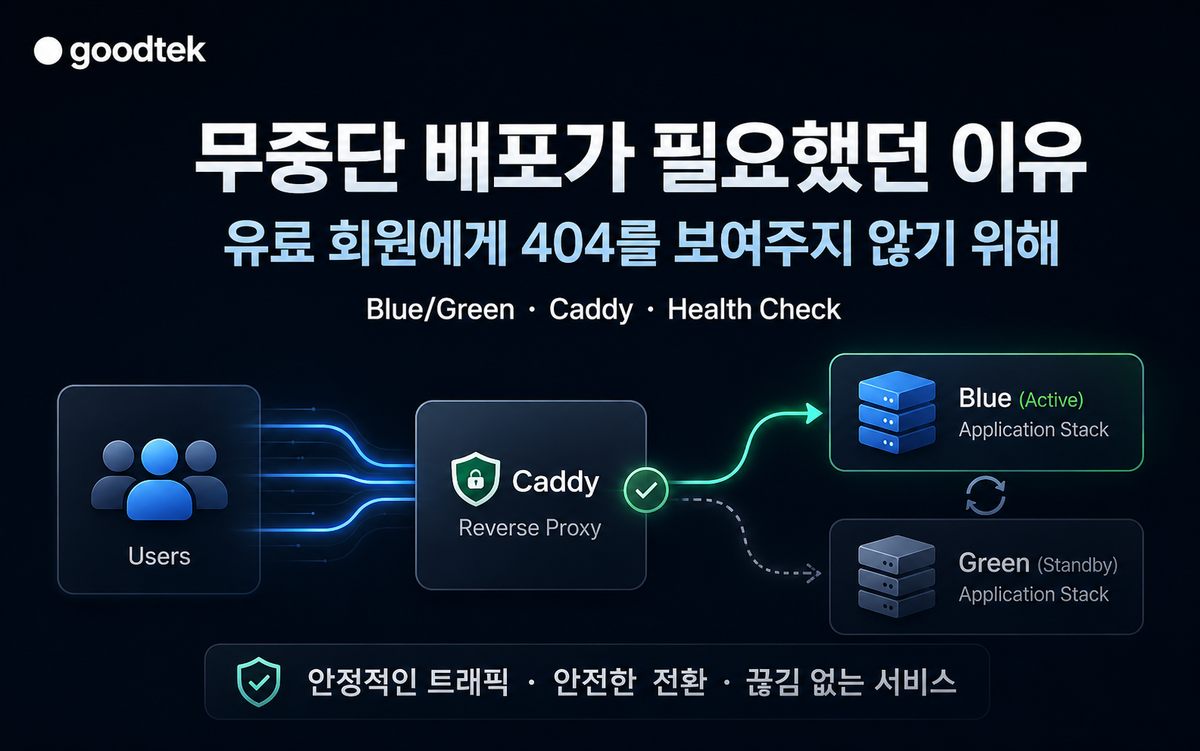
운영 서버에 배포한다는 건 단순히 새 코드를 올리는 일이 아니었습니다.
개발 환경에서는 잠깐 서버가 내려가도 괜찮습니다. 새로 빌드하고, 다시 띄우고, 안 되면 로그를 보고 고치면 됩니다. 하지만 운영 환경은 다릅니다. 그 순간에도 누군가는 페이지를 열고 있고, 누군가는 API 요청을 보내고 있고, 누군가는 유료 회원으로 서비스를 사용하고 있습니다.
배포 때문에 그 사람에게 404 페이지가 보이면 어떻게 될까요.
기술적으로는 “배포 중 잠깐 끊김”이라고 설명할 수 있습니다. 하지만 사용자 입장에서는 그냥 서비스가 불안정한 겁니다. 특히 결제한 사용자라면 더 그렇습니다. 돈을 내고 쓰는 서비스에서 배포 시간마다 화면이 깨진다면, 그건 기능 완성도와 별개로 신뢰를 깎는 일입니다.
그래서 이번 goodtek 운영 배포에서 가장 먼저 정한 기준은 이것이었습니다.
배포는 성공해야 한다.
하지만 그보다 먼저, 배포 중에도 사용자는 계속 서비스를 쓸 수 있어야 한다.
이번 작업은 단순히 prod 배포 스크립트를 만든 일이 아니었습니다. 무중단 배포가 왜 필요한지, 어떤 구조로 구축했는지, 그리고 실제 배포 중 정말 끊김이 없었는지 확인한 과정까지 포함한 운영 기준을 세우는 작업이었습니다.
왜 무중단 배포가 필요했나
처음에는 prod 배포 자동화를 “main에 머지하면 서버에 반영되는 흐름” 정도로 생각했습니다.
CI가 돌고, GHCR에 이미지가 올라가고, prod 서버가 이미지를 pull하고, compose로 컨테이너를 다시 띄우면 됩니다. 구조만 보면 그렇게 복잡해 보이지 않습니다.
하지만 운영 관점에서 다시 보면 가장 위험한 순간은 바로 이 부분입니다.
기존 서비스를 내리고 새 서비스를 올리는 사이.
그 사이에 새 버전이 바로 뜨면 괜찮습니다. 하지만 실제 배포에서는 여러 가지 일이 생깁니다.
| 배포 중 발생 가능한 문제 | 사용자에게 보일 수 있는 결과 |
|---|---|
| 새 이미지 pull 실패 | 기존 서비스가 내려간 상태라면 장애 |
| 환경변수 누락 | API 500 또는 앱 기동 실패 |
| DB 연결 실패 | 로그인, 결제, 콘텐츠 접근 실패 |
| 프록시 설정 오류 | 404 또는 502 |
| 서버 아키텍처 불일치 | 컨테이너 실행 실패 또는 성능 문제 |
이 중 하나라도 배포 중에 터지면, 사용자는 그 문제의 원인을 알 수 없습니다. 그냥 페이지가 안 열리고, 요청이 실패하고, 서비스가 불안정하다고 느낍니다.
그래서 goodtek에서는 배포 기준을 이렇게 바꿨습니다.
| 기존 생각 | 운영 기준 |
|---|---|
| 새 버전을 빨리 올리면 된다 | 새 버전이 준비되기 전까지 기존 버전을 유지해야 한다 |
| 배포 로그가 성공이면 된다 | 공개 URL이 계속 200을 반환해야 한다 |
| 서버에서 컨테이너가 뜨면 된다 | 사용자 트래픽이 끊기지 않아야 한다 |
| 실패하면 다시 고치면 된다 | 실패해도 기존 서비스는 살아 있어야 한다 |
무중단 배포의 목적은 멋진 배포 자동화가 아니라, 배포 실패가 사용자 장애로 번지지 않게 막는 것이었습니다.
핵심은 Blue/Green 구조
이번에 구축한 핵심 구조는 Blue/Green 배포입니다.
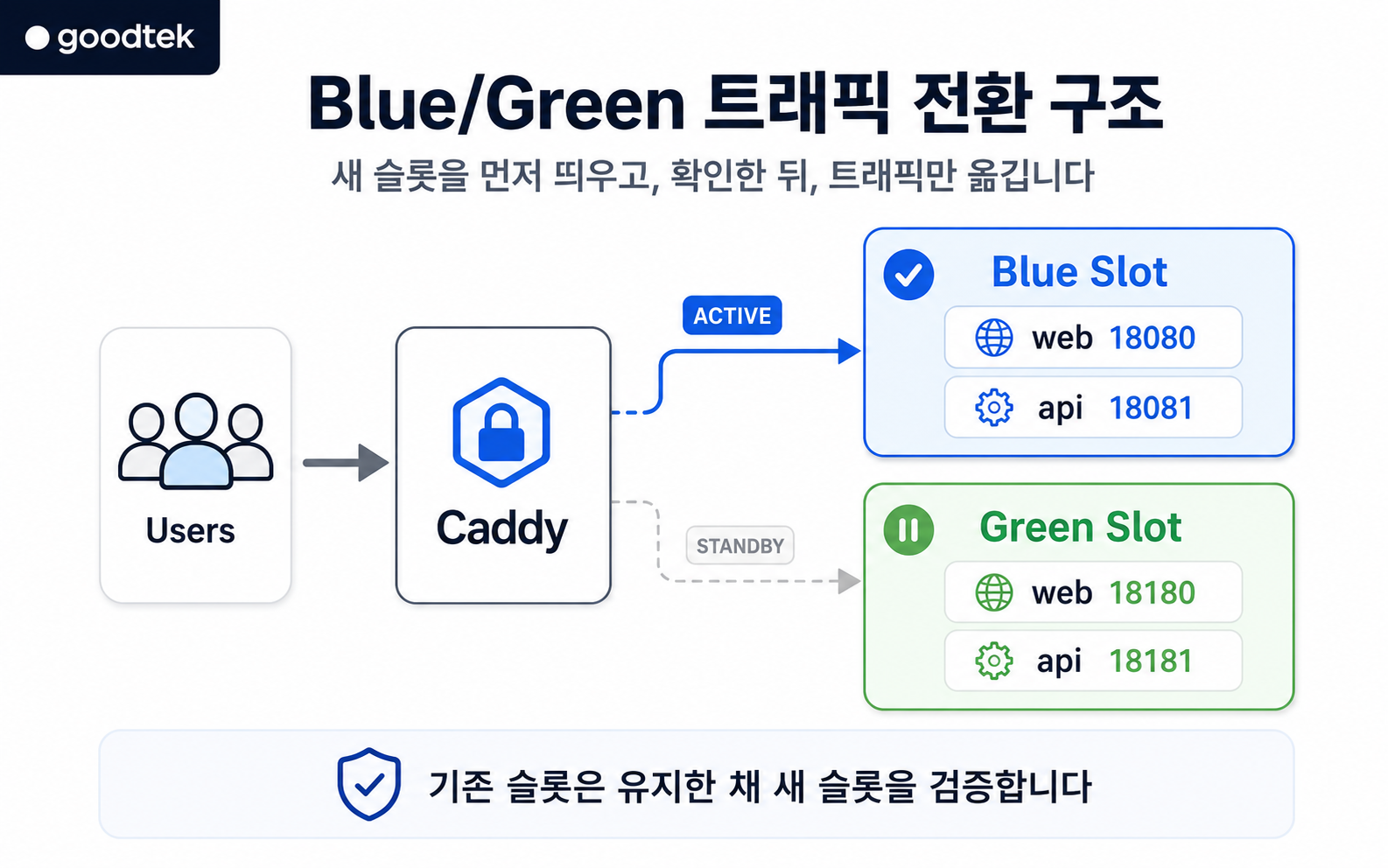
현재 서비스 중인 슬롯을 blue 또는 green 중 하나로 두고, 다음 배포는 반대쪽 슬롯에 먼저 올립니다. 예를 들어 blue가 현재 서비스 중이라면, 새 버전은 green에 먼저 띄웁니다. green이 정상인지 확인한 뒤에만 Caddy가 green을 바라보도록 전환합니다.
production
├─ blue
│ ├─ web : 18080
│ └─ api : 18081
├─ green
│ ├─ web : 18180
│ └─ api : 18181
└─ caddy
├─ current web upstream
└─ current api upstream
포트는 슬롯별로 분리했습니다.
| 슬롯 | Web | API |
|---|---|---|
| blue | 18080 | 18081 |
| green | 18180 | 18181 |
이 구조에서 중요한 점은 기존 슬롯을 먼저 내리지 않는다는 것입니다.
새 슬롯이 완전히 준비되기 전까지 기존 슬롯은 계속 트래픽을 받습니다. 새 슬롯이 내부 health check를 통과하고, Caddy 전환 후 공개 URL health check까지 통과해야 기존 슬롯을 내립니다.
Caddy는 고정하고, upstream만 바꾸기
트래픽 전환은 Caddy에서 처리했습니다.
메인 Caddyfile은 최대한 고정하고, 실제 upstream만 작은 snippet 파일로 분리했습니다.
| 파일 | 역할 | 배포 중 변경 여부 |
|---|---|---|
/etc/caddy/Caddyfile | 도메인, TLS, 라우팅 | 거의 고정 |
/etc/caddy/goodtek-web-upstream.caddy | Web upstream | 배포 때 변경 |
/etc/caddy/goodtek-api-upstream.caddy | API upstream | 배포 때 변경 |
Caddyfile은 이런 식으로 구성했습니다.
goodtek.xyz {
encode gzip
handle /api/* {
import /etc/caddy/goodtek-api-upstream.caddy
}
handle {
import /etc/caddy/goodtek-web-upstream.caddy
}
}
현재 blue가 active라면 snippet은 blue 포트를 봅니다.
reverse_proxy 127.0.0.1:18080
green으로 전환할 때는 snippet이 green 포트를 보도록 바뀝니다.
reverse_proxy 127.0.0.1:18180
이후 Caddy reload를 실행합니다.
이 방식이 마음에 들었던 이유는 운영 중에 건드리는 범위가 작기 때문입니다. 배포 때마다 전체 Caddyfile을 다시 쓰는 방식은 부담이 큽니다. 반면 upstream snippet만 바꾸면 변경 범위가 명확합니다.
운영 자동화에서는 “무엇을 바꿀지”만큼 “무엇을 바꾸지 않을지”도 중요했습니다.
실제 배포 흐름
이번에 정리한 prod 배포 흐름은 다음과 같습니다.
1. 현재 active 슬롯 확인
2. inactive 슬롯 선택
3. GHCR에서 새 이미지 pull
4. inactive 슬롯에 web/api 컨테이너 기동
5. 내부 health check 실행
6. Caddy upstream snippet 변경
7. Caddy reload
8. 공개 URL health check 실행
9. 기존 active 슬롯 종료
10. active-color 기록
각 단계의 목적은 분명합니다.
| 단계 | 목적 |
|---|---|
| active 슬롯 확인 | 현재 사용자 트래픽이 향하는 곳 파악 |
| inactive 슬롯 기동 | 기존 서비스 유지한 채 새 버전 준비 |
| 내부 health check | 새 슬롯이 서버 내부에서 정상인지 확인 |
| Caddy 전환 | 트래픽을 새 슬롯으로 이동 |
| 공개 URL health check | 사용자 관점에서 실제 응답 확인 |
| 기존 슬롯 종료 | 전환 확인 후 안전하게 정리 |
여기서 가장 중요한 단계는 health check입니다.
컨테이너가 떠 있다고 해서 서비스가 정상인 것은 아닙니다. 포트가 열려 있다고 해서 사용자가 페이지를 볼 수 있는 것도 아닙니다. 그래서 내부 check와 외부 check를 나눴습니다.
내부 health check는 새 슬롯이 서버 안에서 정상적으로 응답하는지 확인합니다.
공개 URL health check는 Caddy 전환 이후 실제 도메인 기준으로 사용자가 정상 응답을 받는지 확인합니다.
GHCR, Infisical, arm64까지 맞춰야 했다
무중단 배포 구조만 만든다고 끝나지는 않았습니다. 실제 운영 배포에서는 주변 조건도 맞아야 했습니다.
prod는 dev와 다르게 서버에서 직접 이미지를 빌드하지 않고, CI가 GHCR에 push한 이미지를 prod 서버가 pull하는 방식으로 구성했습니다.
| 환경 | 이미지 처리 방식 |
|---|---|
| dev | 서버에서 직접 build |
| prod | GHCR 이미지 pull |
그래서 prod에는 GHCR pull용 secret이 필요했습니다.
| Secret | 필요 이유 |
|---|---|
GHCR_USERNAME | GHCR 로그인 사용자 |
GHCR_TOKEN | private package pull 권한 |
PROD_CADDY_WEB_UPSTREAM_FILE | web upstream snippet 경로 |
PROD_CADDY_API_UPSTREAM_FILE | api upstream snippet 경로 |
PROD_PROXY_RELOAD_CMD | Caddy reload 명령 |
또 하나 중요한 문제는 서버 아키텍처였습니다.
CI는 GitHub Actions에서 돌고, prod 서버는 arm64였습니다. 처음에는 amd64 이미지가 pull되는 경고가 보였습니다. 그냥 넘어갈 수도 있었지만, 운영 첫 배포에서 플랫폼 불일치를 남기는 건 위험했습니다.
그래서 CI를 multi-arch 이미지로 바꿨습니다.
GHCR image
├─ linux/amd64
└─ linux/arm64
prod server
└─ podman pull --platform linux/arm64
이 변경으로 CI 시간은 늘어났습니다. 하지만 prod 서버가 명확하게 arm64 이미지를 가져오게 되었고, 배포 결과를 더 예측할 수 있게 됐습니다.
빠른 배포보다 먼저 필요한 것은 예측 가능한 배포였습니다.
실제로 끊김이 없는지 테스트하기
구조를 만들었다고 바로 믿을 수는 없었습니다.
그래서 실제 Deploy Prod를 실행하는 동안 외부에서 공개 URL을 계속 호출했습니다. 배포 로그만 보는 대신, 사용자 입장에서 계속 서비스가 살아 있는지 확인한 것입니다.
테스트는 단순했습니다.
while true; do
api=$(curl -sf -o /dev/null -w '%{http_code}' https://goodtek.xyz/api/health || echo FAIL)
web=$(curl -sf -o /dev/null -w '%{http_code}' https://goodtek.xyz/ko || echo FAIL)
echo "api:$api web:$web"
sleep 1
done
이 테스트의 목적은 명확했습니다.
배포 중 어느 순간이라도 API나 Web이 끊기면 FAIL, 404, 502 같은 결과가 바로 보입니다.
기대했던 흐름은 이렇습니다.
| 배포 시점 | 사용자 트래픽 | 기대 응답 |
|---|---|---|
| 배포 시작 전 | 기존 슬롯 | 200 |
| 새 슬롯 기동 중 | 기존 슬롯 | 200 |
| 새 슬롯 health check 중 | 기존 슬롯 | 200 |
| Caddy 전환 순간 | 새 슬롯 | 200 |
| 기존 슬롯 종료 후 | 새 슬롯 | 200 |
1초 간격으로 실제 배포 중 확인한 결과, 공개 URL 기준으로 api:200, web:200 응답이 계속 이어졌습니다. Caddy가 새 슬롯으로 전환되는 순간에도 실패 응답이 보이지 않았습니다.
즉, 이번 배포는 단순히 “스크립트가 성공했다”가 아니라 배포 중 사용자 관점에서도 끊김 없이 응답이 유지되는지 확인한 배포였습니다.

active-color로 현재 트래픽 위치 확인
배포 후에는 현재 active 슬롯을 기록했습니다.
.deploy/active-color
이 파일이 blue라면 Caddy upstream도 blue 포트를 바라봐야 합니다.
| active-color | Web upstream | API upstream |
|---|---|---|
| blue | 18080 | 18081 |
| green | 18180 | 18181 |
이 확인이 필요한 이유는 단순합니다.
배포가 끝난 뒤에도 사람이 현재 상태를 확인할 수 있어야 하기 때문입니다. 자동화가 아무리 좋아도 운영자는 지금 트래픽이 어디로 가는지 볼 수 있어야 합니다.
좋은 배포 자동화는 조용히 실행되는 것에서 끝나지 않습니다. 검증 가능한 흔적을 남겨야 합니다.
이번 구축의 핵심 정리
이번 무중단 배포 구축에서 실제로 만든 핵심은 다음과 같습니다.
| 구성 요소 | 역할 |
|---|---|
| Blue/Green 슬롯 | 새 버전을 기존 서비스 옆에 먼저 기동 |
| Caddy upstream snippet | 트래픽 전환 범위를 작게 유지 |
| 내부 health check | 새 슬롯이 서버 내부에서 정상인지 확인 |
| public health check | 사용자 도메인 기준 응답 확인 |
| GHCR image pull | prod 서버에서 검증된 이미지 사용 |
| Infisical prod secret | 운영 배포 조건을 코드 밖에서 관리 |
| active-color 기록 | 현재 서비스 슬롯 추적 |
| curl loop test | 배포 중 실제 끊김 여부 확인 |
이 중 하나만으로는 무중단 배포가 되지 않습니다. 여러 요소가 연결되어야 합니다.
CI
└─ GHCR image push
└─ prod server pull
└─ inactive slot up
└─ health check
└─ Caddy switch
└─ public health check
└─ old slot down
흐름에서 가장 중요한 원칙은 하나입니다.
새 버전이 검증되기 전까지 기존 버전을 절대 내리지 않는다.
배포 성공보다 중요한 것
이번 작업을 하면서 기준이 분명해졌습니다.
운영에서 배포 성공은 GitHub Actions에 초록 체크가 뜨는 것만으로는 부족합니다. 서버에서 스크립트가 끝나는 것도 부족합니다. 컨테이너가 떠 있는 것도 부족합니다.
사용자 입장에서 계속 서비스가 열려야 합니다.
특히 유료 회원이 있는 서비스라면 더 그렇습니다. 유료 회원은 우리가 어떤 브랜치 전략을 쓰는지, 어떤 CI를 돌리는지, 어떤 이미지 레지스트리를 쓰는지 모릅니다. 그냥 접속했을 때 서비스가 안정적으로 동작하기를 기대합니다.
그 기대를 깨지 않기 위해 무중단 배포가 필요했습니다.
이번 goodtek prod 배포는 그 기준을 처음으로 실제 운영 구조에 넣은 작업이었습니다. Blue/Green 슬롯을 만들고, Caddy 전환을 분리하고, GHCR와 Infisical을 연결하고, arm64 이미지까지 맞춘 뒤, 실제 배포 중 끊김 테스트까지 확인했습니다.
결과적으로 배포 중 공개 URL은 계속 200을 반환했습니다.
그제야 “prod 배포 자동화가 됐다”는 말보다 조금 더 중요한 말을 할 수 있었습니다.
배포하는 동안에도 사용자는 서비스를 계속 사용할 수 있었다.
다음에 더 다듬을 것
이번에 무중단 배포의 기본 골격은 갖췄습니다. 하지만 운영 자동화는 한 번에 끝나는 작업이 아닙니다.
다음에는 CI 시간을 줄이는 문제를 봐야 합니다. 현재 multi-arch 빌드 때문에 시간이 길어졌고, prod가 arm64만 쓴다면 arm64 전용 이미지 push로 줄일 수 있습니다. Deploy Dev와 Deploy Prod 트리거가 연쇄적으로 많이 뜨는 문제도 정리할 필요가 있습니다.
하지만 그건 다음 단계입니다.
이번 단계에서 가장 중요한 건 배포 버튼을 누를 때마다 “잠깐 끊겨도 괜찮겠지”라고 넘기지 않게 된 것입니다.
goodtek의 운영 기준은 이제 조금 더 분명해졌습니다.
배포는 개발자의 일이지만, 배포 순간의 경험은 사용자의 것입니다.